1 chapter 2: basics of business analytics 2.1 overview of techniques 2.2 data management 2.3 data...
TRANSCRIPT

1
Chapter 2: Basics of Business Analytics
2.1 Overview of Techniques
2.2 Data Management
2.3 Data Difficulties
2.4 SAS Enterprise Miner: A Primer
2.5 Honest Assessment
2.6 Methodology
2.7 Recommended Reading

2
Chapter 2: Basics of Business Analytics
2.1 Overview of Techniques2.1 Overview of Techniques
2.2 Data Management
2.3 Data Difficulties
2.4 SAS Enterprise Miner: A Primer
2.5 Honest Assessment
2.6 Methodology
2.7 Recommended Reading

3
Objectives Name two major types of data mining analyses. List techniques for supervised and unsupervised
analyses.
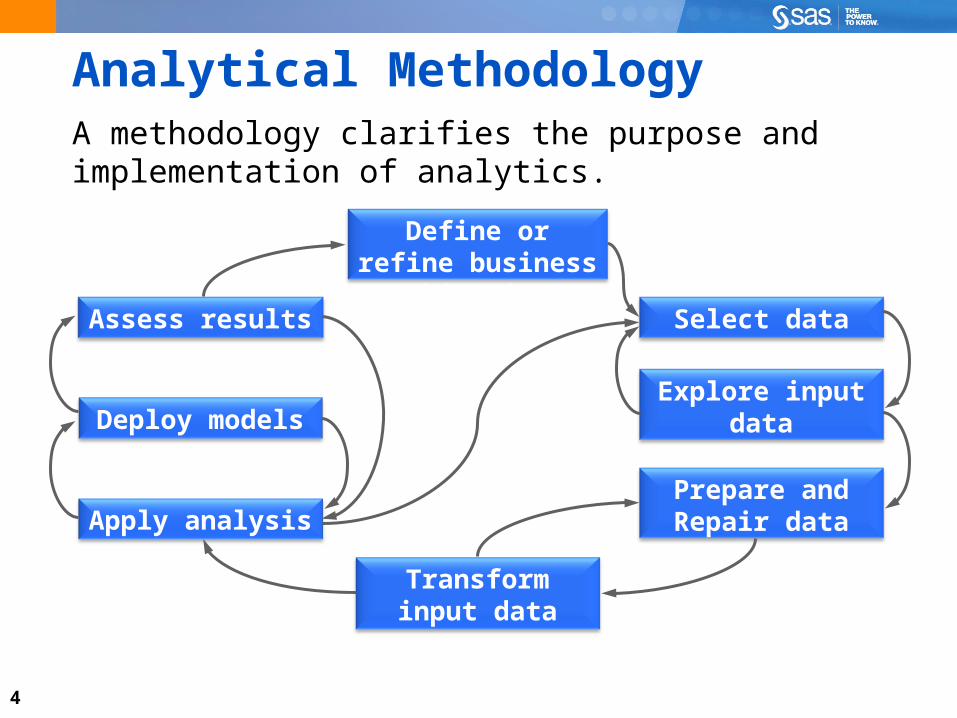
4
Analytical MethodologyA methodology clarifies the purpose and implementation of analytics.
Select data
Define or refine business objective
Assess results
Deploy modelsExplore input
data
Prepare and Repair data
Transform input data
Apply analysis

5
Business Analytics and Data MiningData mining is a key part of effective business analytics.
Components of data mining: data management data management data management customer segmentation predictive modeling forecasting standard and nonstandard statistical modeling
practices

6
What Is Data Mining? Information Technology
– complicated database queries Machine Learning
– inductive learning from examples Statistics
– what we were taught not to do

7
Translation for This CourseSegmentation Unsupervised classification
– cluster analysis– association rules
other techniques
Predictive Modeling Supervised classification
– linear regression– logistic regression– decision trees
other techniques
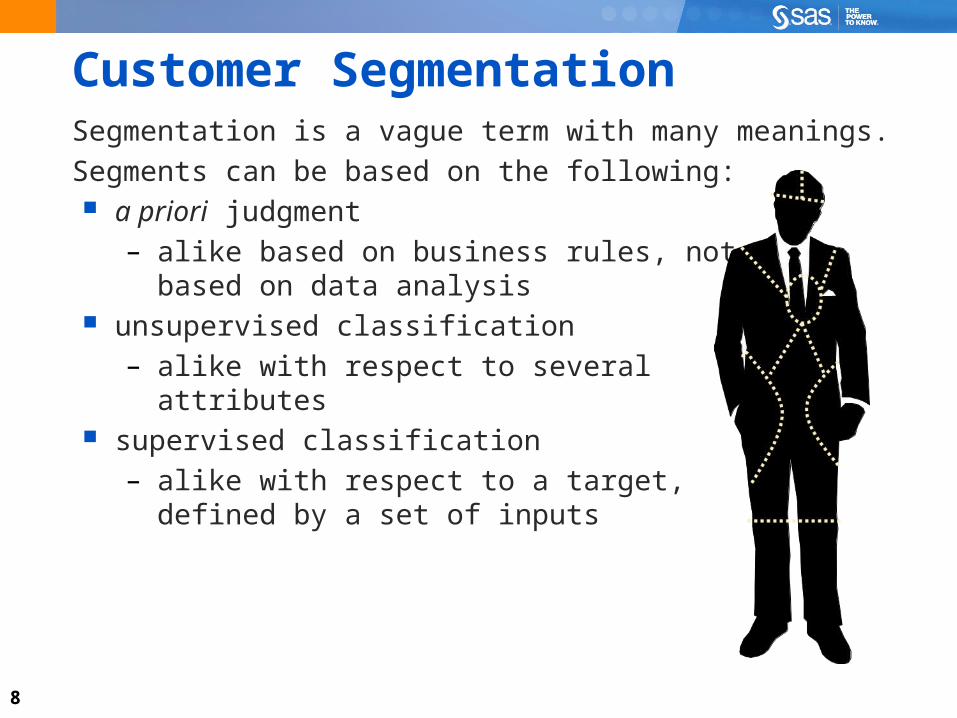
8
Customer SegmentationSegmentation is a vague term with many meanings.
Segments can be based on the following: a priori judgment
– alike based on business rules, not based on data analysis
unsupervised classification– alike with respect to several
attributes supervised classification
– alike with respect to a target, defined by a set of inputs

9
Segmentation: Unsupervised Classification
case 1:
inputs, ? case 2: inputs, ? case 3: inputs, ? case 4: inputs, ? case 5: inputs, ?
Training Data
new case
new case
case 1: inputs, cluster 1 case 2: inputs, cluster 3 case 3: inputs, cluster 2 case 4: inputs, cluster 1 case 5: inputs, cluster 2
Training Data
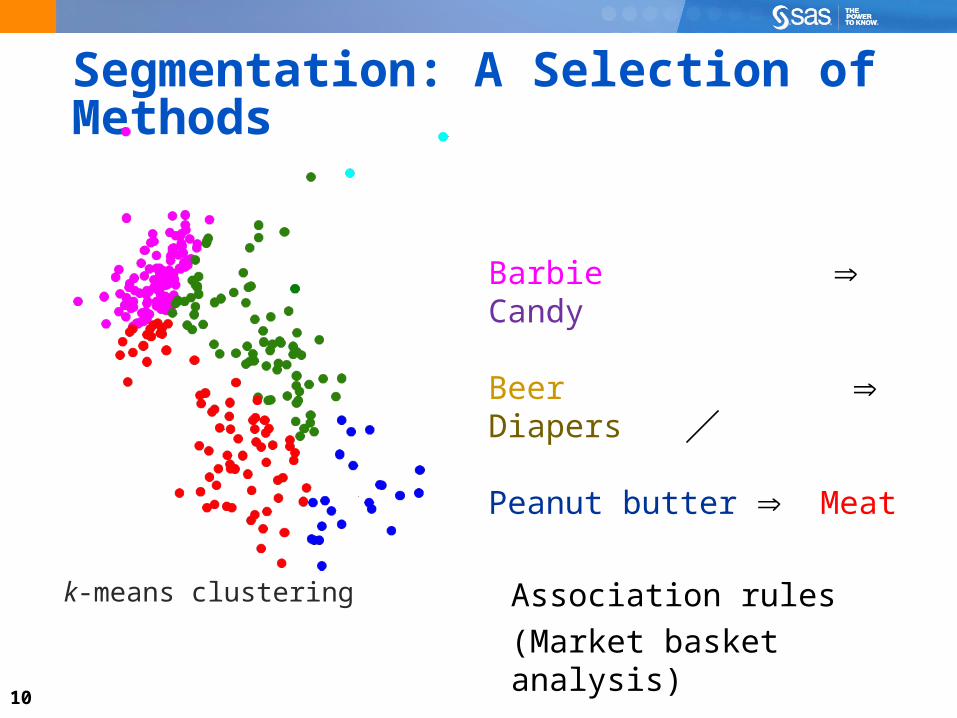
10
Segmentation: A Selection of Methods
k-means clustering Association rules
(Market basket analysis)
Barbie Candy
Beer Diapers
Peanut butter Meat
11
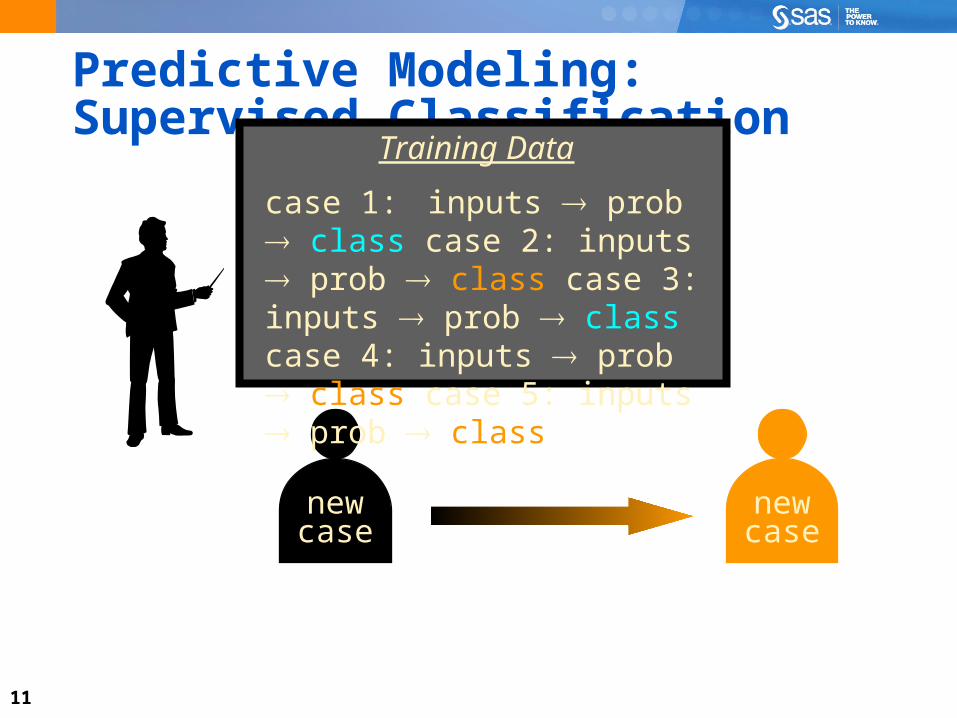
Predictive Modeling: Supervised Classification
case 1: inputs prob class case 2: inputs prob class case 3: inputs prob class case 4: inputs prob class case 5: inputs prob class
Training Data
new case
new case

12
Predictive Modeling: Supervised Classification
......
......
......
......
......
...
...
...
...
...
...
...
...
...
Inputs
Cases
Target
...
...

13
2.01 PollThe primary difference between supervised and unsupervised classification is whether a dependent, or target, variable is known.
Yes
No

14
2.01 Poll – Correct AnswerThe primary difference between supervised and unsupervised classification is whether a dependent, or target, variable is known.
Yes
No

15
Types of Targets Logistic Regression
– event/no event (binary target)– class label (multiclass problem)
Regression– continuous outcome
Survival Analysis– time-to-event (possibly censored)

16
Discrete Targets Health Care
– target = favorable/unfavorable outcome Credit Scoring
– target = defaulted/did not default on a loan Marketing
– target = purchased product A, B, C, or none

17
Continuous Targets Health Care Outcomes
– target = hospital length of stay, hospital cost Liquidity Management
– target = amount of money at an ATM machine or in a branch vault
Merchandise Returns– target = time between purchase and return
(censored)

18
Application: Target Marketing Cases = customers, prospects, suspects,
households Inputs = geographics, demographics,
psychometrics, RFM variables Target = response to a past or test solicitation Action = target high-responding segments
of customers in future campaigns

19
Application: Attrition Prediction/Defection Detection Cases = existing customers Inputs = payment history, product/service
usage, demographics
Target = churn, brand switching, cancellation, defection
Action = customer loyalty promotion

20
Application: Fraud Detection Cases = past transaction or claims Inputs = particulars and circumstances Target = fraud, abuse, deception Action = impede or investigate suspicious
cases

21
Application: Credit Scoring Cases = past applicants Inputs = application information, credit bureau
reports Target = default, charge-off, serious
delinquency,repossession, foreclosure
Action = accept or reject future applicants forcredit
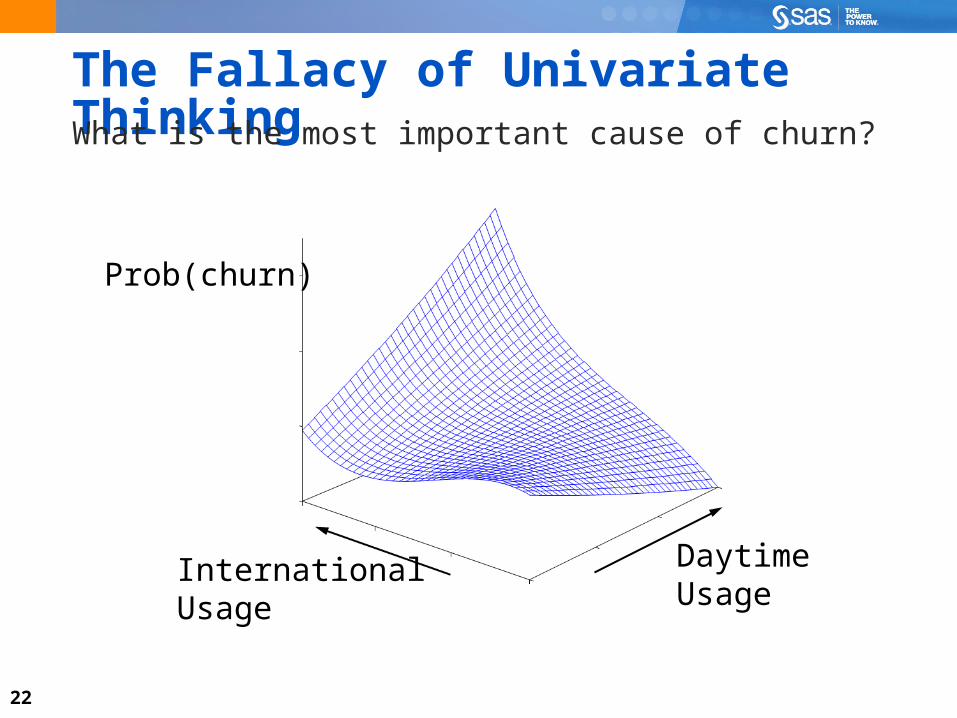
22
The Fallacy of Univariate ThinkingWhat is the most important cause of churn?
Prob(churn)
InternationalUsage
DaytimeUsage
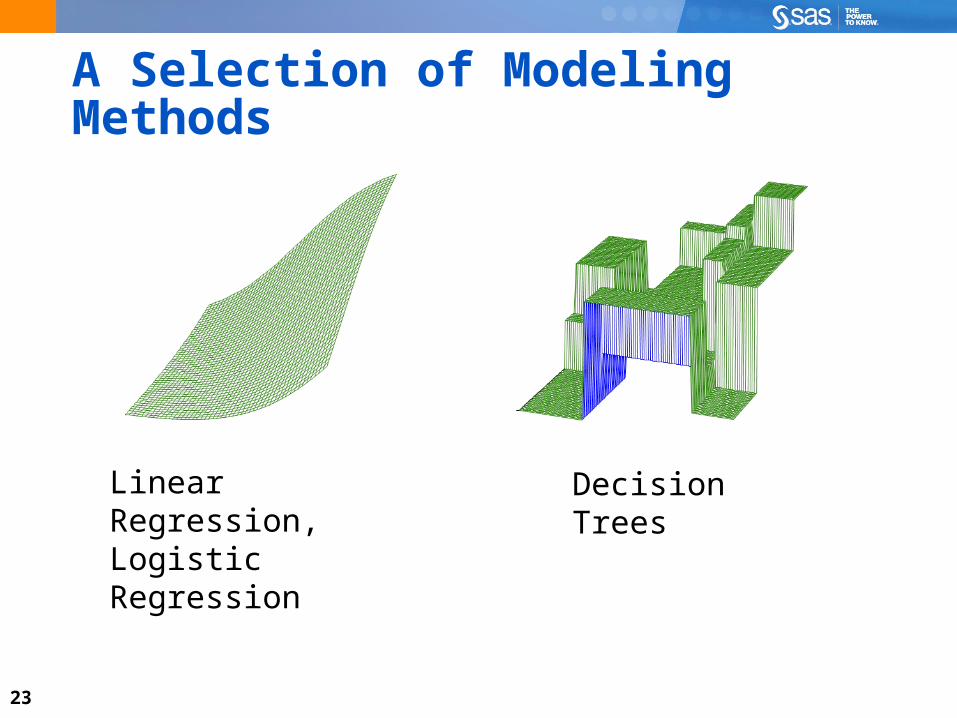
23
A Selection of Modeling Methods
Linear Regression,Logistic Regression
DecisionTrees
24
Transactions
Hard Target Search
...
25
Transactions
Hard Target Search
Fraud
26
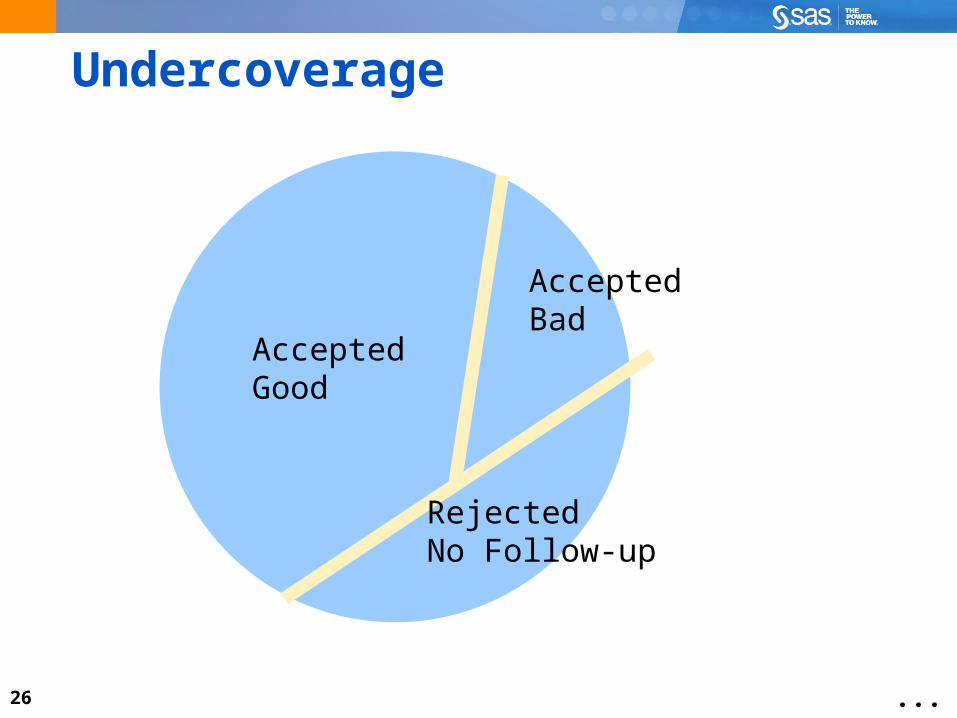
Undercoverage
AcceptedGood
RejectedNo Follow-up
AcceptedBad
...
27
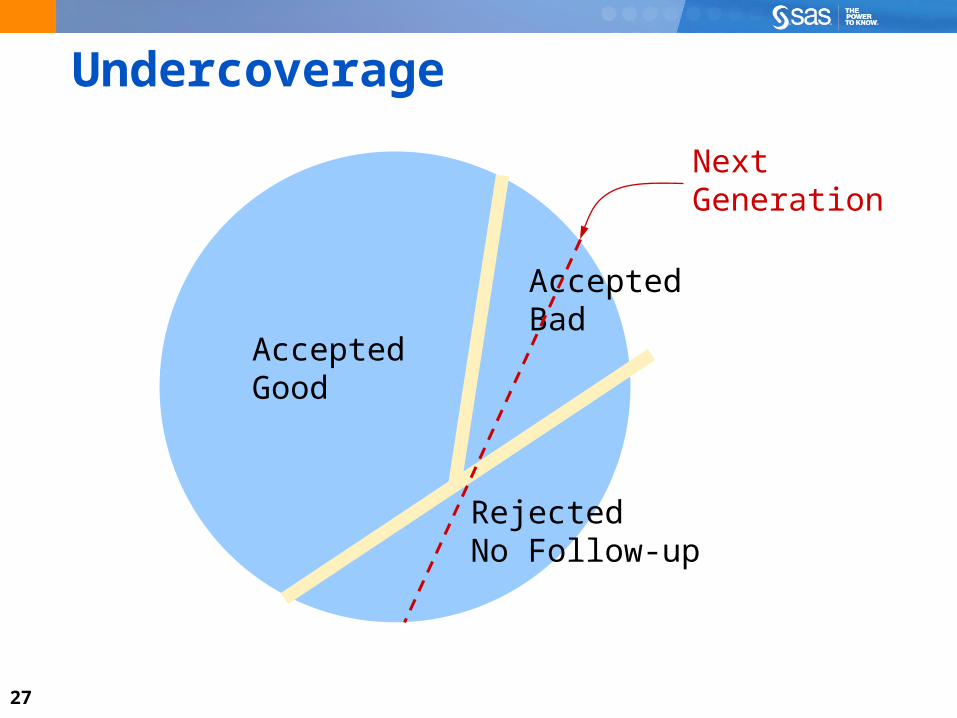
Undercoverage
AcceptedGood
RejectedNo Follow-up
AcceptedBad
NextGeneration

28
2.02 PollImpediments to high-quality business data can lie in the very nature of business decision-making: the worst prospects are not marketed to. Therefore, information about the sort of customer that they would be (profitable or unprofitable) is usually unknown, making supervised classification more difficult.
Yes
No
29
2.02 Poll – Correct AnswerImpediments to high-quality business data can lie in the very nature of business decision-making: the worst prospects are not marketed to. Therefore, information about the sort of customer that they would be (profitable or unprofitable) is usually unknown, making supervised classification more difficult.
Yes
No

30
Chapter 2: Basics of Business Analytics
2.1 Overview of Techniques
2.2 Data Management2.2 Data Management
2.3 Data Difficulties
2.4 SAS Enterprise Miner: A Primer
2.5 Honest Assessment
2.6 Methodology
2.7 Recommended Reading

31
Objectives Explain the concept of data integration. Describe SAS Enterprise Guide and how it fits in with
data integration and management for business analytics.

32
Data Management and Business AnalyticsData management brings together data components that can exist on multiple machines, from different software vendors, throughout the organization.
Data management is the foundation for business analytics. Without correctly consolidated data, those working in the analytics, reporting, and solutions areas might not be working with the most current, accurate data.
Advanced Analytics
Basic Analytics
Reporting

33
Managing Data for Business Analytics Business analytics requires data management
activities such as data access, movement, transformation, aggregation, and augmentation.
These tasks can involve many different types of data (for example, simple flat files, files with comma-separated values, Microsoft Excel files, SAS tables, and Oracle tables).
The data likely combines individual transactions, customer summaries, product summaries, or other levels of data granularity – or some combination of those things.

34
Planning from the Top Down
What data will help you answer these questions?
What mission-critical questions must be answered?
What data do you havethat will help you buildthe needed data?
35
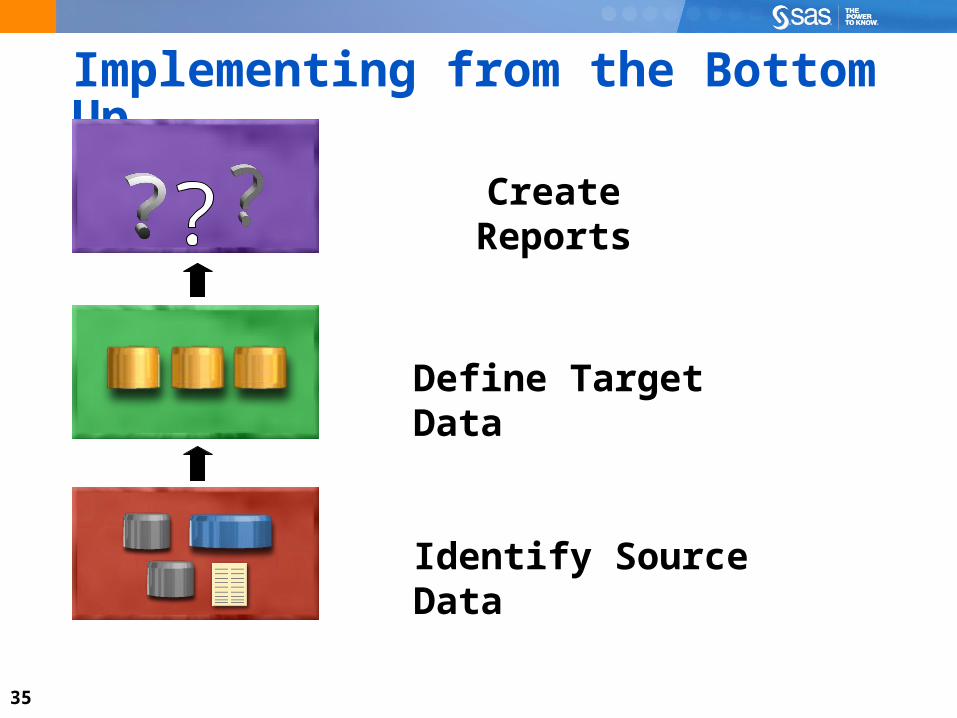
Implementing from the Bottom Up
Define Target Data
Identify Source Data
Create Reports

36
Collaboration Is Key to Business Analytics
Business Expert IT Expert Analytical Expert

37
Data Marts: Tying Questions to DataStated simplistically, data marts are implemented at organizations because there are questions that must be answered.
Data is typically collected in daily operations but might not be organized in a way that answers the questions.
An IT professional can use the questions and the data collected from daily operations to construct the tables for a data warehouse or data mart.

38
Building a Data MartFoundation of a Data Mart
Create target tables.
Identify target tables.
Identify source tables.
Building the foundation of the data mart consists of the three basic steps listed above.

39
Analytic Objective Example
39
From a population of existing clients with sufficient tenure and other qualifications, identify a subset most likely to have interest in an insurance investment product (INS).
Business:
Objective:
Large financial institution

40
Financial Institution’s DataThe financial institution has highly detailed data that is challenging to transform into a structure suitable for predictive modeling. As is the case with most organizations, the financial institution has a large amount of data about its customers, products, and employees. Much of this information is stored in transactional systems in various formats.
Using SAS Enterprise Guide, this transactional information is extracted, transformed, and loaded into a data mart for the Marketing Department.
You continue to work with this data set for some basic exploratory analysis and reporting.
41
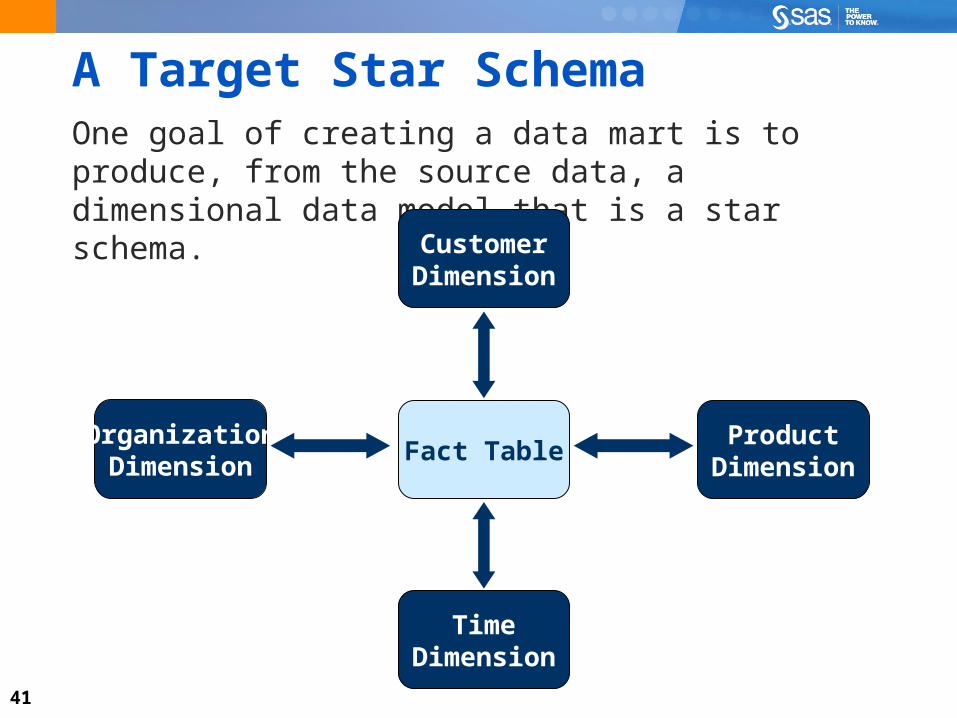
A Target Star SchemaOne goal of creating a data mart is to produce, from the source data, a dimensional data model that is a star schema.
Fact TableProduct
Dimension
TimeDimension
OrganizationDimension
CustomerDimension
42
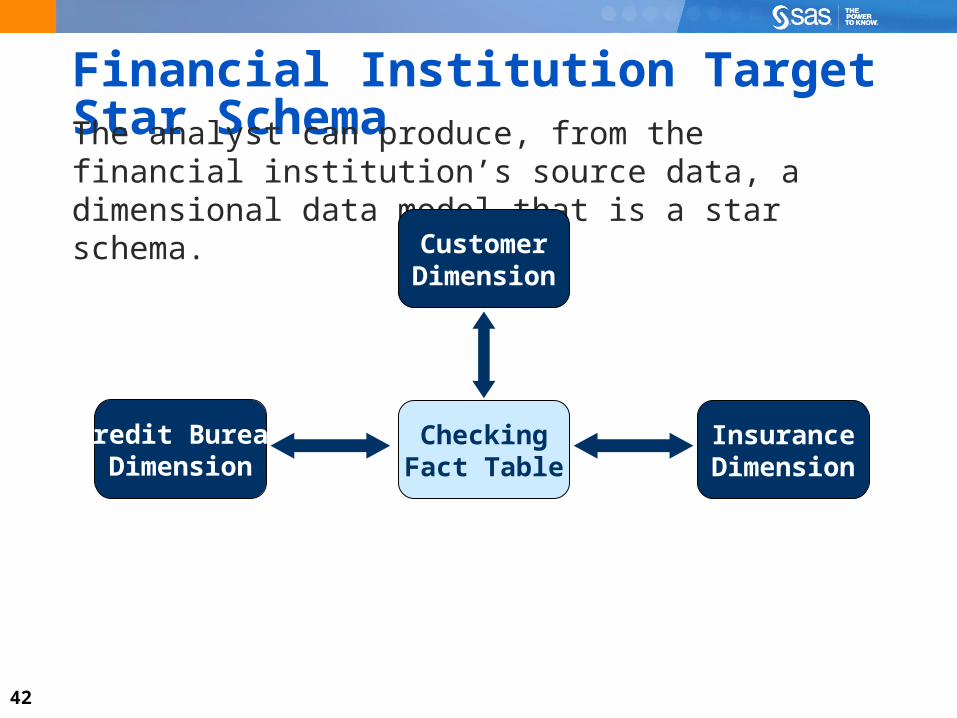
Financial Institution Target Star SchemaThe analyst can produce, from the financial institution’s source data, a dimensional data model that is a star schema.
CheckingFact Table
InsuranceDimension
Credit BureauDimension
CustomerDimension

43
Checking_transactions Table The checking_transactions table contains the following attributes, one per a record fact.
This fact contains some measured or observed variables.
The fact table contains the data, and the dimensions identify each tuple in the data.
CHECKING_ID
CHKING_TRANS_DT
CHKING_TRANS_AMT
CHKING_TRANS_CHANNEL_CD
CHKING_TRANS_METHOD_CD
CHKING_TRANS_TYPE_CD

44
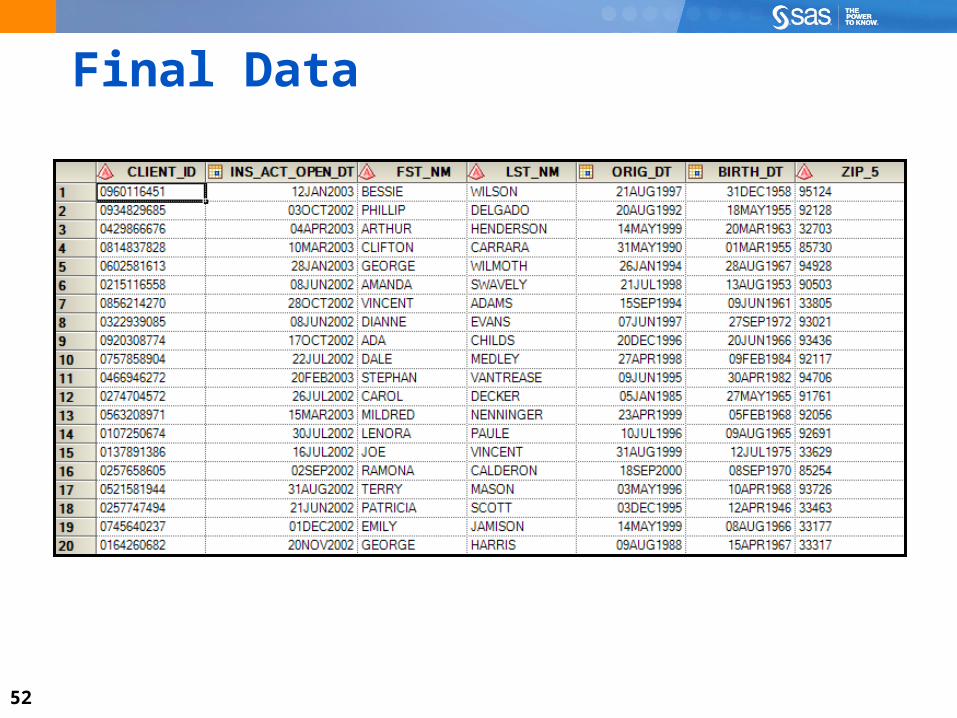
Client Table The client table contains client information.
In practice, this data set could also contain address and other information.
For this demonstration, only CLIENT_ID, FST_NM, LST_NM, ORIG_DT, BIRTH_DT, and ZIP_5are used.
CLIENT_ID
FST_NM
LST_NM
ORIG_DT
BIRTH_DT
ZIP_5
45
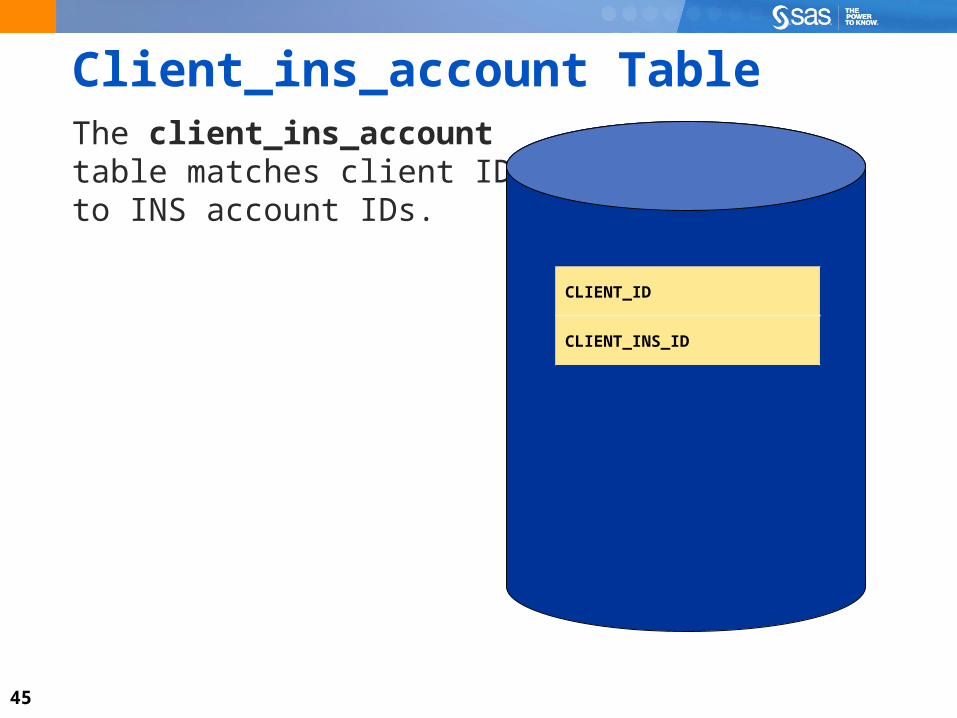
Client_ins_account Table The client_ins_account table matches client IDs to INS account IDs.
CLIENT_ID
CLIENT_INS_ID

46
Ins_account Table The ins_account table contains the insurance account information.
In practice, this data set would contain other fields such as rates, maturity dates, and initial deposit amount.
For this demonstration, only INS_ACT_ID and INS_ACT_OPEN_DT are used.
INS_ACT_ID
INS_ACT_OPEN_DT
…
…
…
…

47
Credit_bureau Table The credit_bureau table contains credit bureau information.
In practice, this data set could contain credit scores from more than one credit bureau and also a history of credit scores.
CLIENT_ID
TL_CNT
FST_TL_TR
FICO_CR_SCR
CREDIT_YQ

48
Advantages of Data Marts There is one version of the truth. Downstream tables are updated as source data is
updated, so analyses are always based on the latest information.
The problem of a proliferation of spreadsheets is avoided.
Information is clearly identified by standardized variable names and data types.
Multiple users can access the same data.

49
SAS Enterprise Guide OverviewSAS Enterprise Guide can be used for data management, as well as a wide variety of other tasks: data exploration querying and reporting graphical analysis statistical analysis scoring

50
Example: Financial Institution Data ManagementThe head of Marketing wants to know which customers have the highest propensity for buying insurance products from the institution.
This could present a cross-selling opportunity.
Create part of an analytical data mart by combining information from many tables: checking account data, customer records, insurance data, and credit bureau information.
51
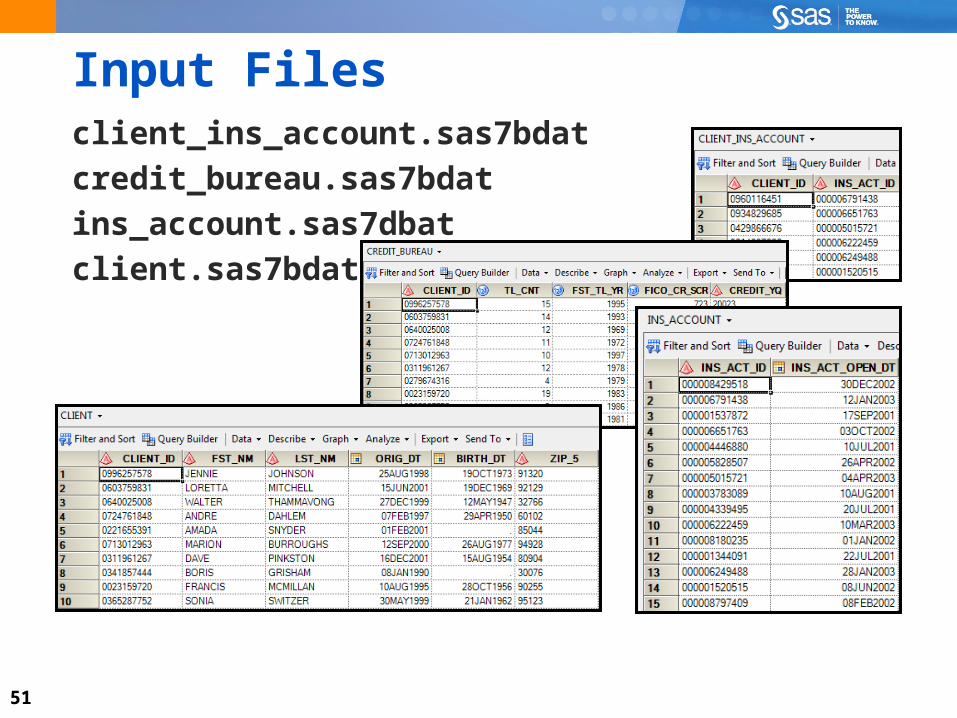
Input Filesclient_ins_account.sas7bdat
credit_bureau.sas7bdat
ins_account.sas7dbat
client.sas7bdat
52
Final Data

53
A Data Management Process Using SAS Enterprise Guide
Financial Institution Case Study
Task: Join several SAS tables and use separate sampling to obtain a training data set.

54
Exploring the Data and Creating a ReportInvestigate the distribution of credit scores. Create a report of credit scores by customers without
insurance and customers with insurance.
Does age have an influence on credit scores? Which customers have the highest credit scores, young customers or older customers? Create a graph of credit scores by age.
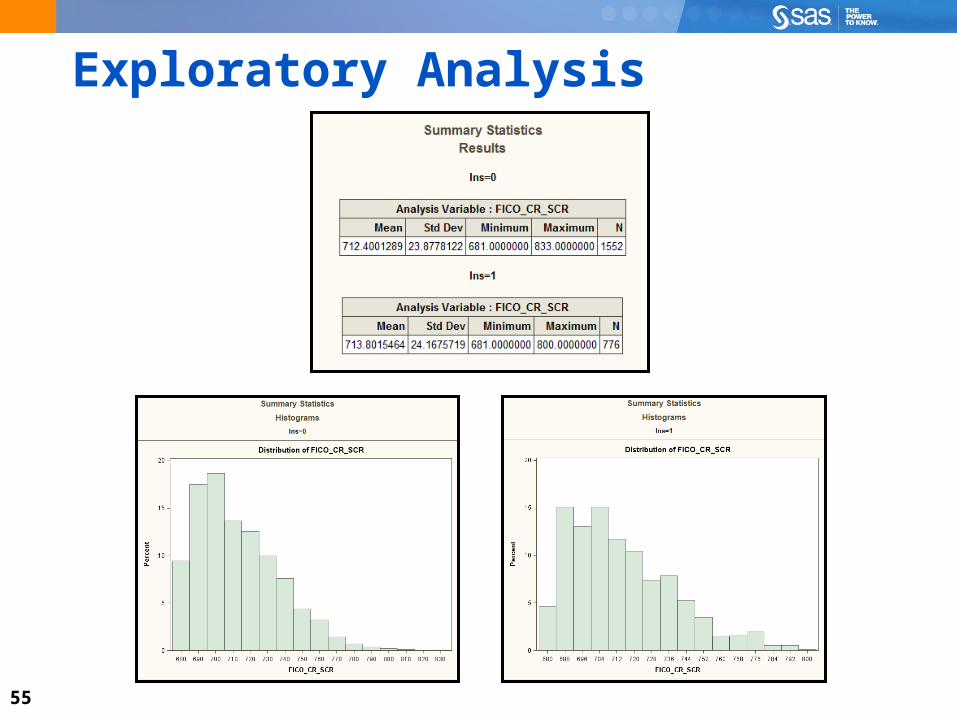
55
Exploratory Analysis

56
Exploring the Data and Creating a Basic Report
Financial Institution Case Study
Task: Investigate the distribution of credit scores by creating a report of credit scores by customers without insurance and customers with insurance.

57
Graphical Exploration
Financial Institution Case Study
Task: Create a graph of credit scores by age.

58
Idea Exchange What conclusions would you draw from this basic data
exploration? Are there additional plots or reports that you would like to explore from the orders data to help you better understand your customers and their propensity to buy insurance?
What additional data would you need to help you make a case to the head of the Marketing Department that marketing dollars should be spent in a particular way?

59
Chapter 2: Basics of Business Analytics
2.1 Overview of Techniques
2.2 Data Management
2.3 Data Difficulties2.3 Data Difficulties
2.4 SAS Enterprise Miner: A Primer
2.5 Honest Assessment
2.6 Methodology
2.7 Recommended Reading

60
Objectives Identify several of the challenges of data mining and
present ways to address these challenges.

61
Initial Challenges in Data Mining1. What do I want to predict?
2. What level of granularity is needed to obtain data about the customer?
...

62
Initial Challenges in Data Mining1. What do I want to predict?
a transaction an individual a household a store a sales team
2. What level of granularity is needed to obtain data about the customer?
...

63
Initial Challenges in Data Mining1. What do I want to predict?
a transaction an individual a household a store a sales team
2. What level of granularity is needed to obtain data about the customer? transactional regional daily monthly other

64
2.03 Multiple Answer PollWhich of the following might constitute a case in a predictive model?
a. a household
b. loan amount
c. an individual
d. the number of products purchased
e. a company
f. a ZIP code
g. salary

65
2.03 Multiple Answer Poll – Correct AnswersWhich of the following might constitute a case in a predictive model?
a. a household
b. loan amount
c. an individual
d. the number of products purchased
e. a company
f. a ZIP code
g. salary

66
Typical Data Mining Time Line
Projected:
Actual:
Dreaded:
Needed:
Data Preparation Data Analysis
Allotted Time
(Data Acquisition)

67
Data ChallengesWhat identifies a unit?
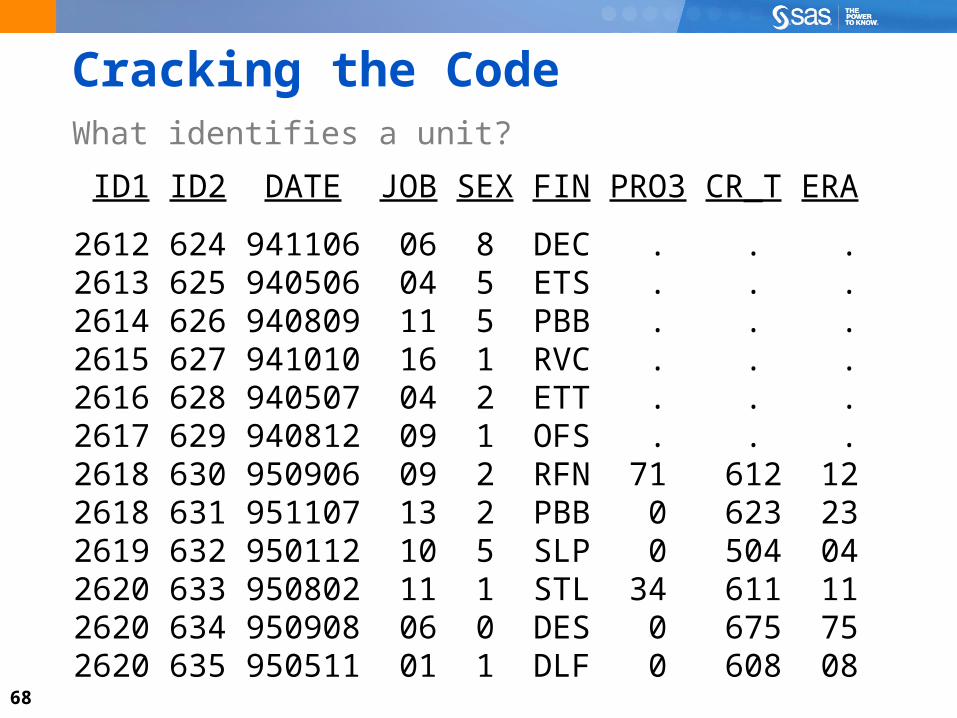
68
ID1 ID2 DATE JOB SEX FIN PRO3 CR_T ERA
2612 624 941106 06 8 DEC . . .2613 625 940506 04 5 ETS . . .2614 626 940809 11 5 PBB . . .2615 627 941010 16 1 RVC . . .2616 628 940507 04 2 ETT . . .2617 629 940812 09 1 OFS . . .2618 630 950906 09 2 RFN 71 612 12 2618 631 951107 13 2 PBB 0 623 232619 632 950112 10 5 SLP 0 504 042620 633 950802 11 1 STL 34 611 112620 634 950908 06 0 DES 0 675 752620 635 950511 01 1 DLF 0 608 08
Cracking the CodeWhat identifies a unit?

69
Data ChallengesWhat should the data look like to perform an analysis?
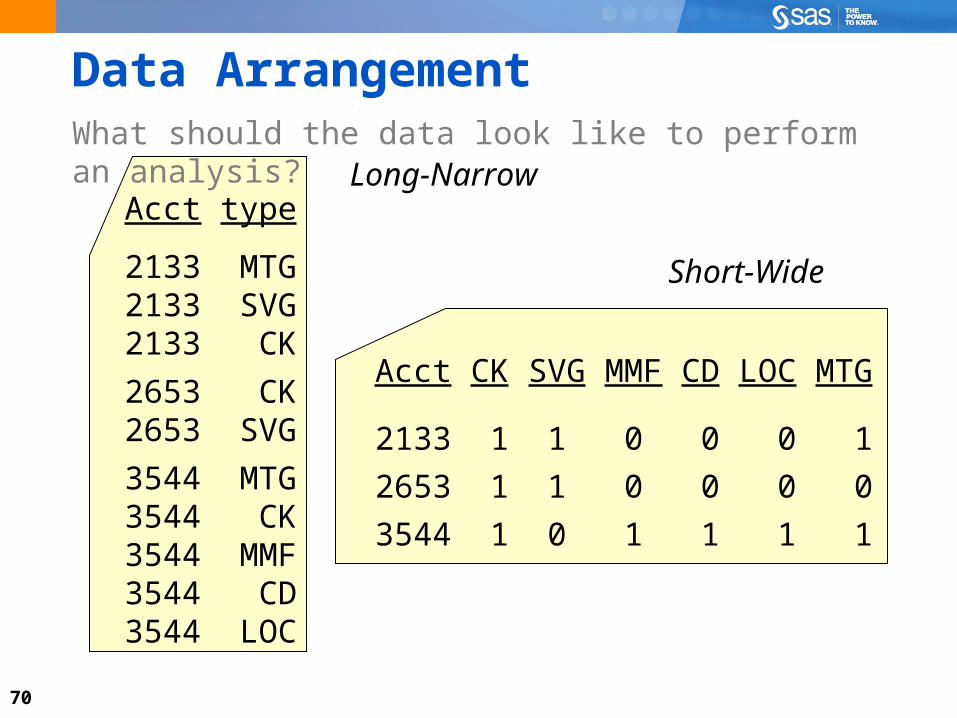
70
Data ArrangementWhat should the data look like to perform an analysis?
Acct type
2133 MTG2133 SVG2133 CK
2653 CK2653 SVG
3544 MTG3544 CK3544 MMF3544 CD3544 LOC
Acct CK SVG MMF CD LOC MTG
2133 1 1 0 0 0 1
2653 1 1 0 0 0 0
3544 1 0 1 1 1 1
Long-Narrow
Short-Wide

71
Data ChallengesWhat variables do I need?
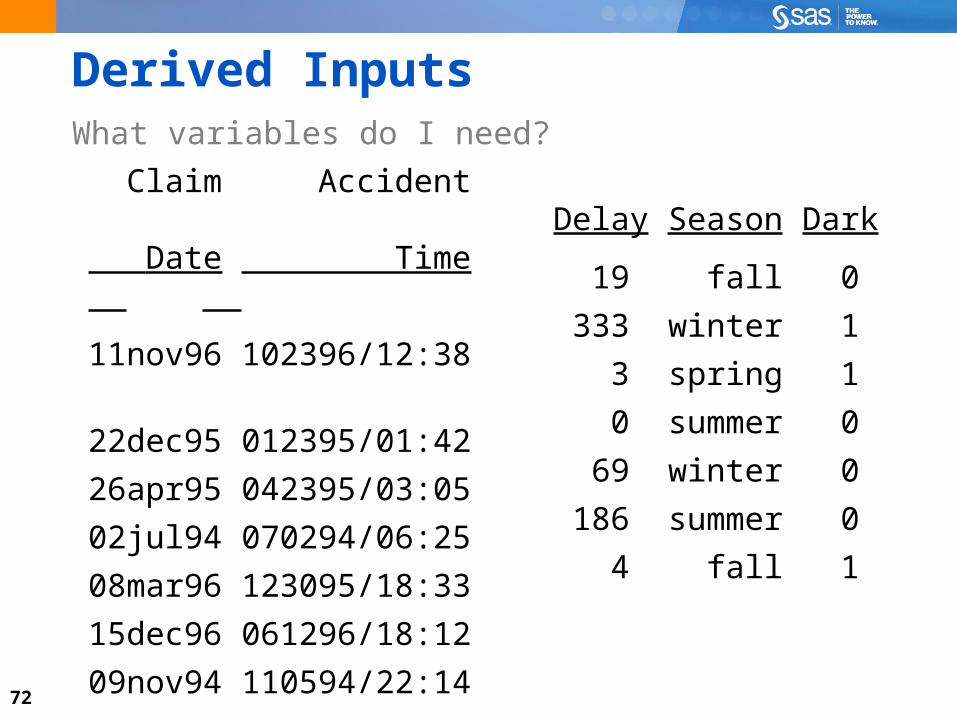
72
Derived InputsWhat variables do I need?
Claim Accident Date Time
11nov96 102396/12:38
22dec95 012395/01:42
26apr95 042395/03:05
02jul94 070294/06:25
08mar96 123095/18:33
15dec96 061296/18:12
09nov94 110594/22:14
Delay Season Dark
19 fall 0
333 winter 1
3 spring 1
0 summer 0
69 winter 0
186 summer 0
4 fall 1
73
Data ChallengesHow do I convert my data to the proper level of granularity?
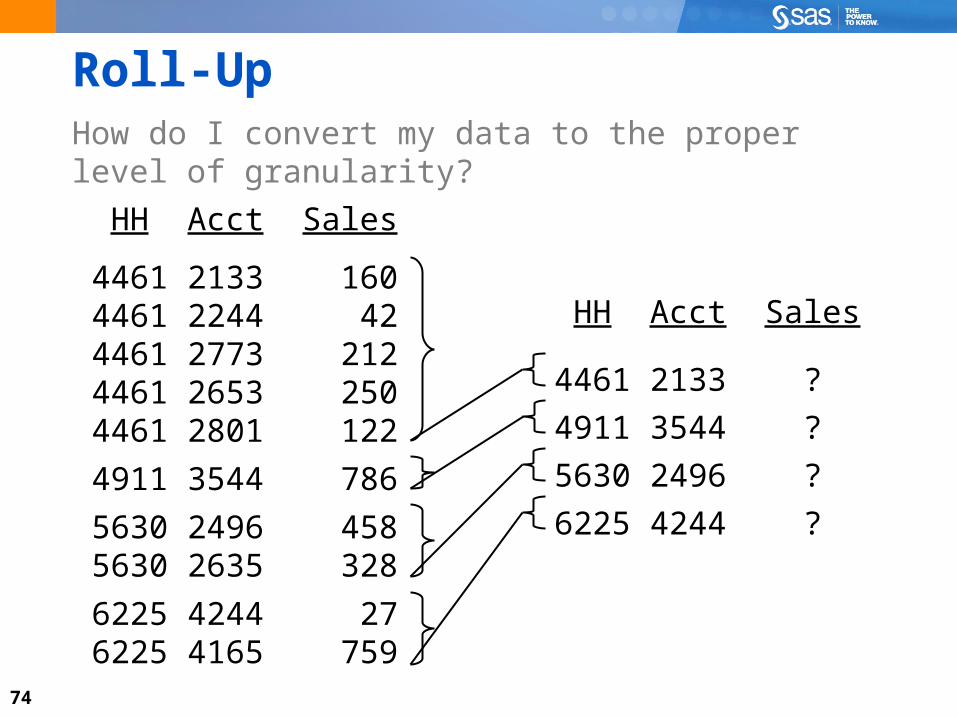
74
Roll-UpHow do I convert my data to the proper level of granularity?
HH Acct Sales
4461 2133 1604461 2244 424461 2773 2124461 2653 2504461 2801 122
4911 3544 786
5630 2496 458 5630 2635 328
6225 4244 276225 4165 759
HH Acct Sales
4461 2133 ?
4911 3544 ?
5630 2496 ?
6225 4244 ?
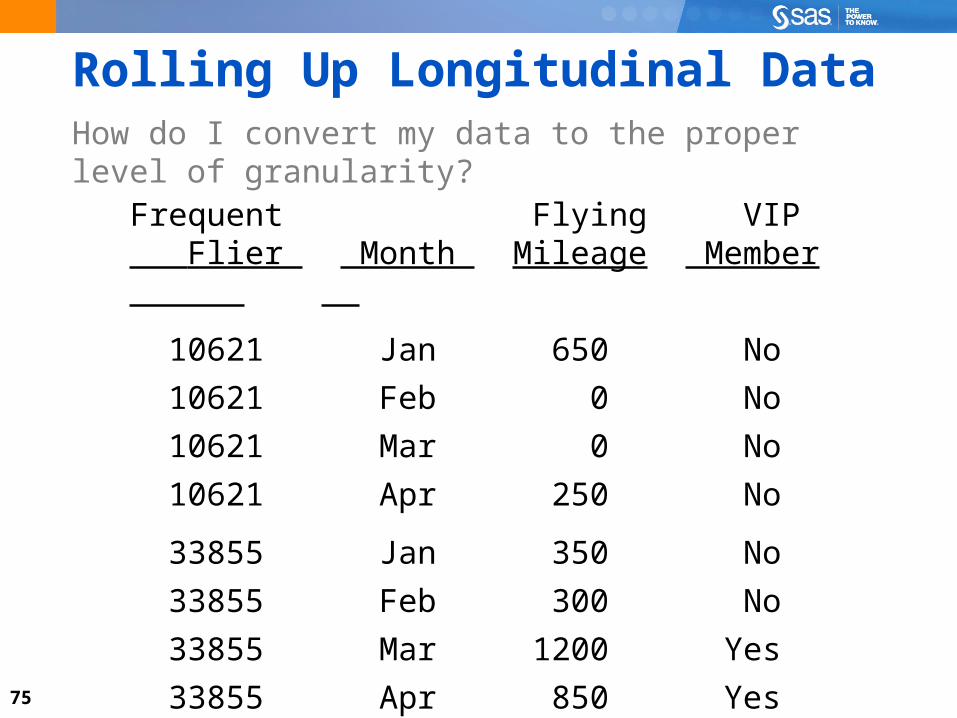
75
Rolling Up Longitudinal DataHow do I convert my data to the proper level of granularity?
Frequent Flying VIP Flier Month Mileage Member
10621 Jan 650 No
10621 Feb 0 No
10621 Mar 0 No
10621 Apr 250 No
33855 Jan 350 No
33855 Feb 300 No
33855 Mar 1200 Yes
33855 Apr 850 Yes

76
Data ChallengesWhat sorts of raw data quality problems can I expect?
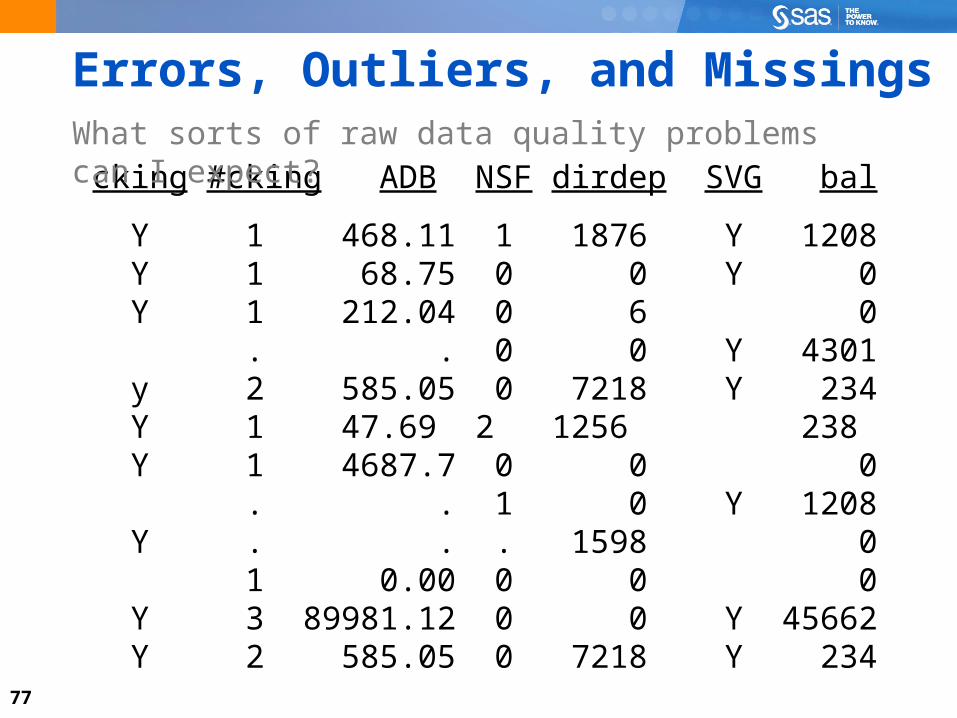
77
cking #cking ADB NSF dirdep SVG bal
Y 1 468.11 1 1876 Y 1208 Y 1 68.75 0 0 Y 0 Y 1 212.04 0 6 0 . . 0 0 Y 4301 y 2 585.05 0 7218 Y 234 Y 1 47.69 2 1256 238 Y 1 4687.7 0 0 0 . . 1 0 Y 1208 Y . . . 1598 0 1 0.00 0 0 0 Y 3 89981.12 0 0 Y 45662 Y 2 585.05 0 7218 Y 234
Errors, Outliers, and MissingsWhat sorts of raw data quality problems can I expect?
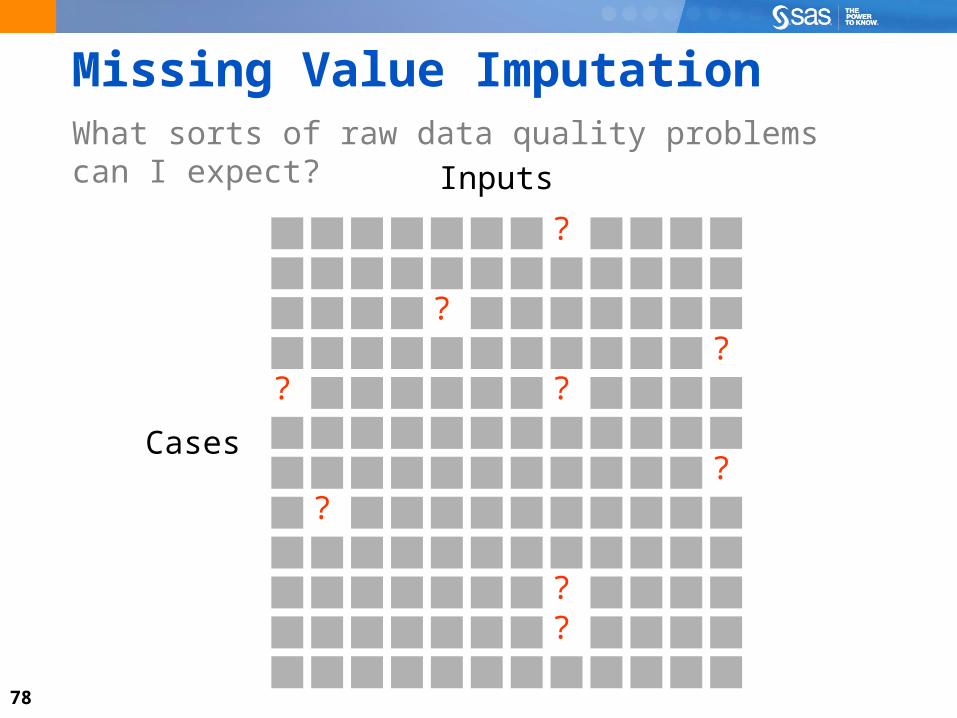
78
Missing Value ImputationWhat sorts of raw data quality problems can I expect?
Cases
Inputs
?
?
?
?
?
?
??
?

79
Data ChallengesCan I (more importantly, should I) analyze all the data that I have?
All the observations?
All the variables?
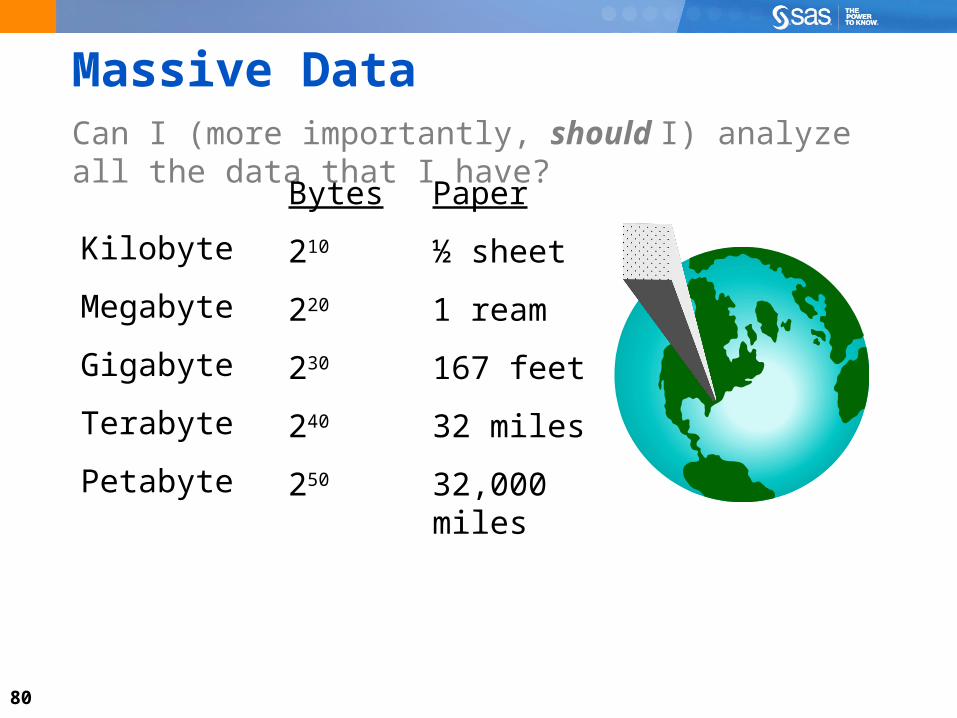
80
Massive DataCan I (more importantly, should I) analyze all the data that I have?
Kilobyte
Megabyte
Gigabyte
Terabyte
Petabyte
Bytes
210
220
230
240
250
Paper
½ sheet
1 ream
167 feet
32 miles
32,000 miles

81
SamplingCan I (more importantly, should I) analyze all the data that I have?
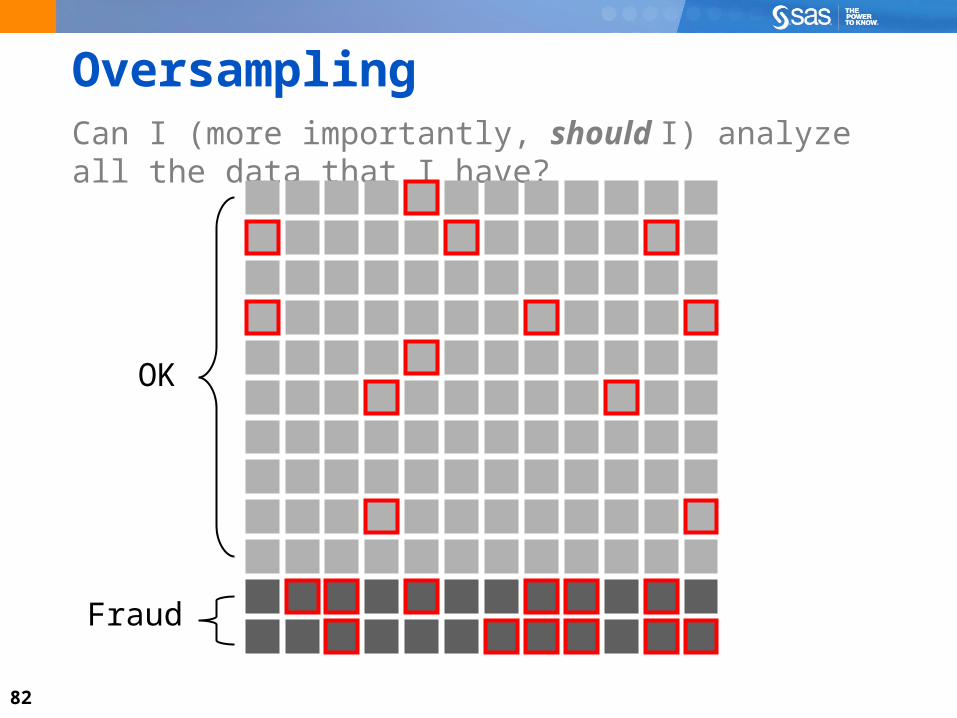
82
OversamplingCan I (more importantly, should I) analyze all the data that I have?
OK
Fraud

83
The Curse of DimensionalityCan I (more importantly, should I) analyze all the data that I have?
1-D
2-D
3-D
84
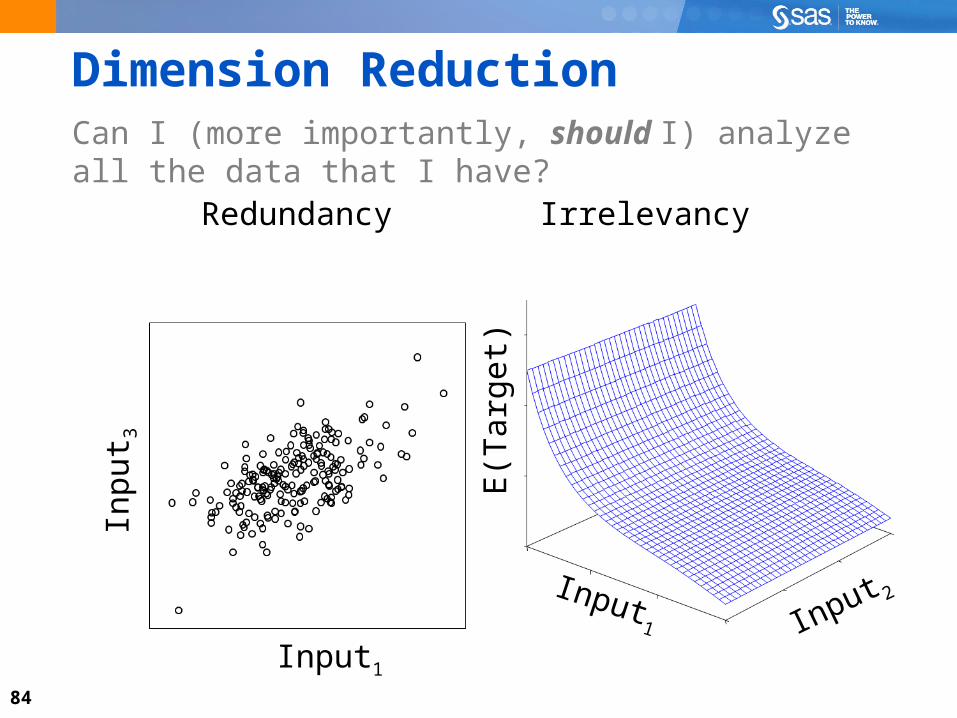
Dimension ReductionCan I (more importantly, should I) analyze all the data that I have?
Inpu
t 3
Input1
Redundancy
Input 2Input1
E(T
arge
t)
Irrelevancy

85
2.04 Multiple Answer PollWhich of the following statements are true?
a. The more data you can get, the better.
b. Too many variables can make it difficult to detect patterns in data.
c. Too few variables can make it difficult to learn interesting facts about the data.
d. Cases with missing values should generally be deleted from modeling.

86
2.04 Multiple Answer Poll – Correct AnswersWhich of the following statements are true?
a. The more data you can get, the better.
b. Too many variables can make it difficult to detect patterns in data.
c. Too few variables can make it difficult to learn interesting facts about the data.
d. Cases with missing values should generally be deleted from modeling.

87
Chapter 2: Basics of Business Analytics
2.1 Overview of Techniques
2.2 Data Management
2.3 Data Difficulties
2.4 SAS Enterprise Miner: A Primer2.4 SAS Enterprise Miner: A Primer
2.5 Honest Assessment
2.6 Methodology
2.7 Recommended Reading

88
Objectives Describe the basic navigation of SAS Enterprise Miner.
88
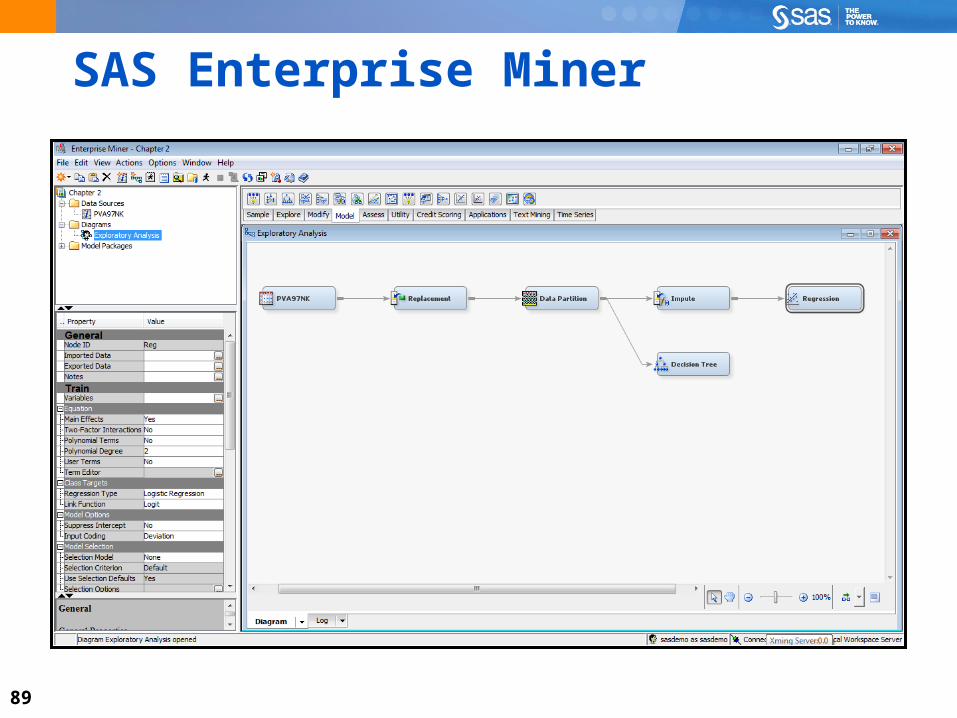
89
SAS Enterprise Miner
90
SAS Enterprise Miner – Interface Tour
Menu bar and shortcut buttons
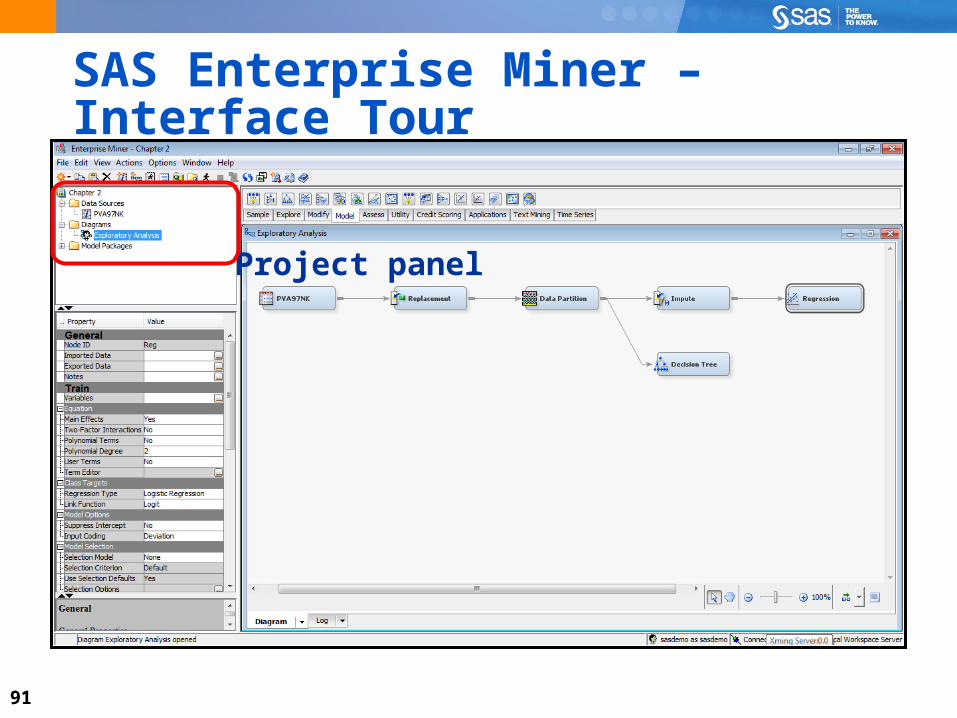
91
SAS Enterprise Miner – Interface Tour
Project panel
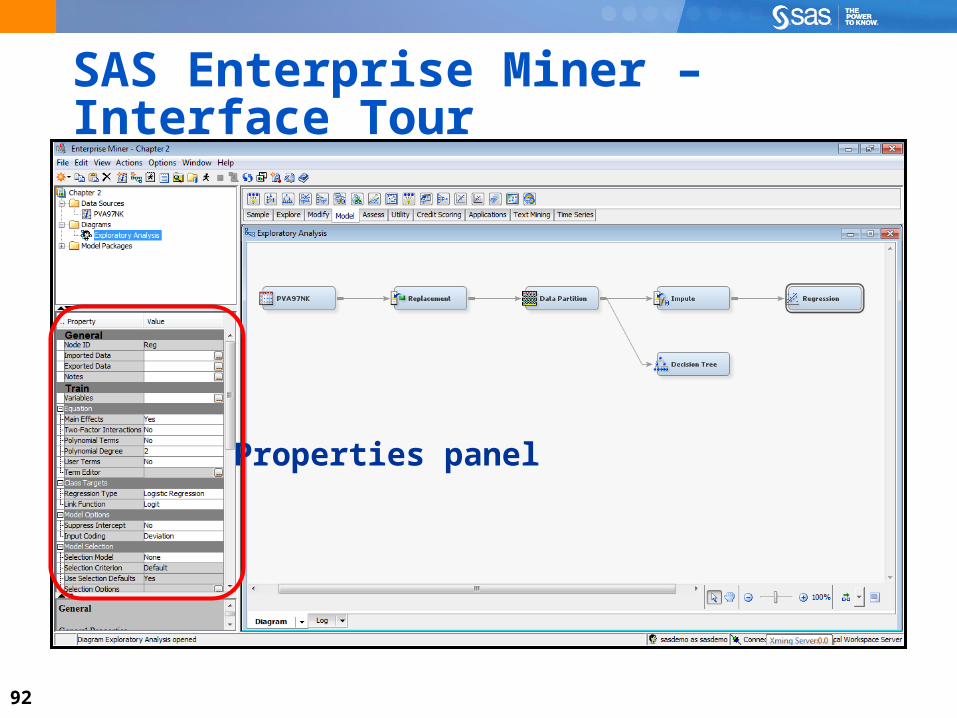
92
SAS Enterprise Miner – Interface Tour
Properties panel
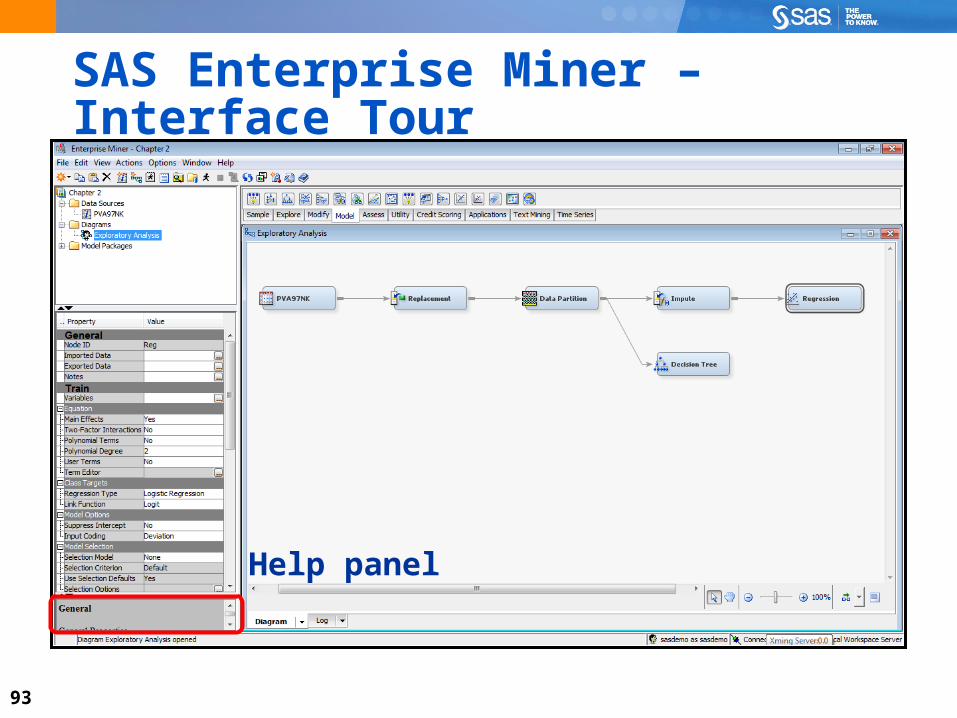
93
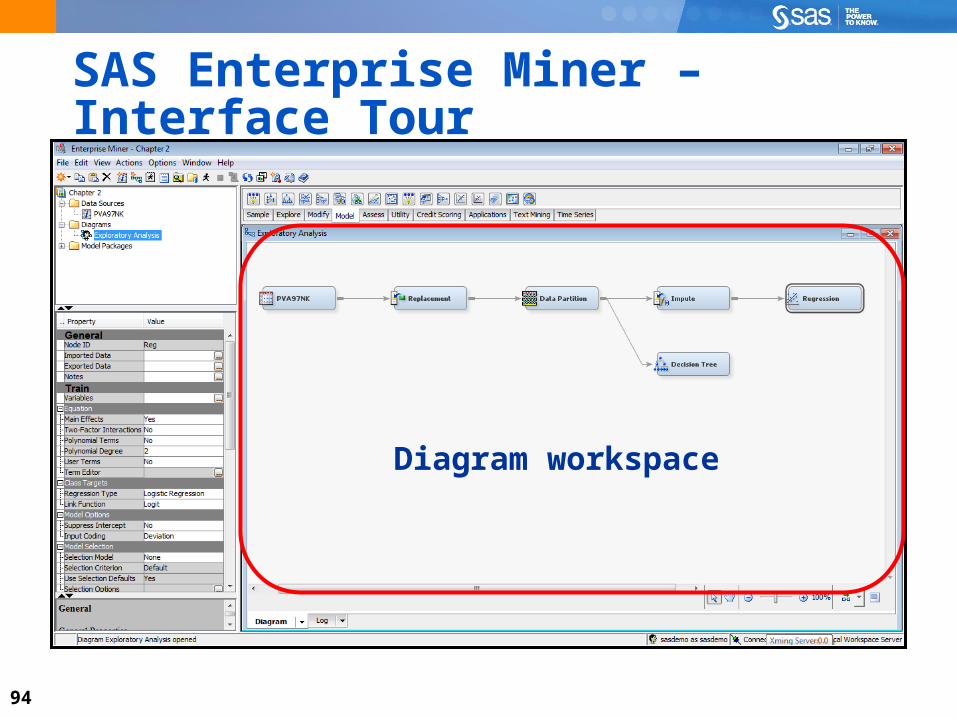
SAS Enterprise Miner – Interface Tour
Help panel
94
SAS Enterprise Miner – Interface Tour
Diagram workspace

95
SAS Enterprise Miner – Interface Tour
Process flow
96
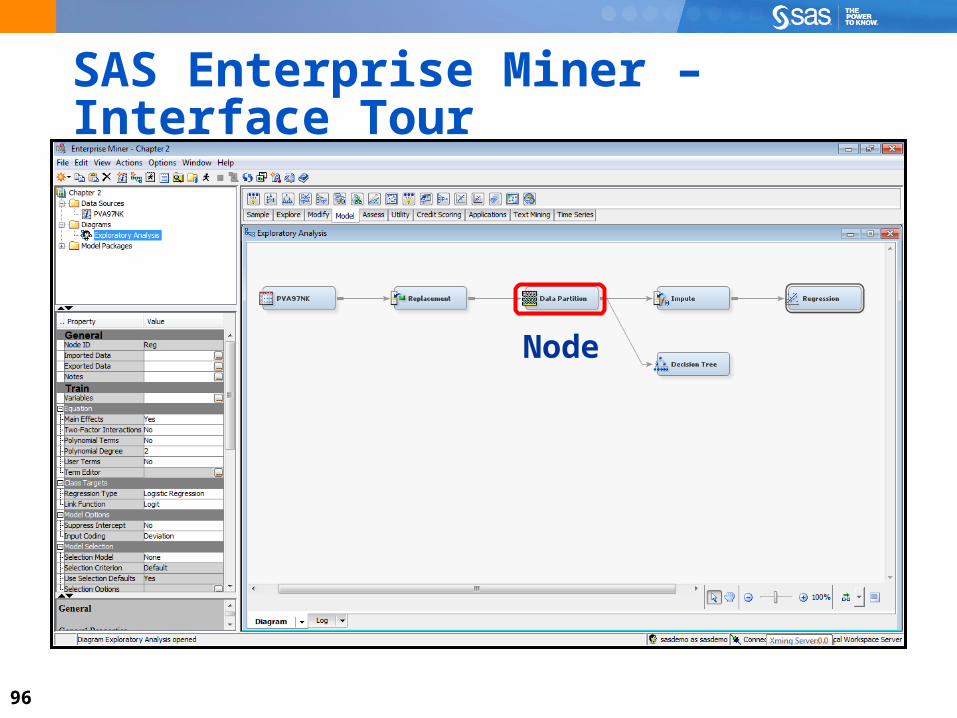
SAS Enterprise Miner – Interface Tour
Node
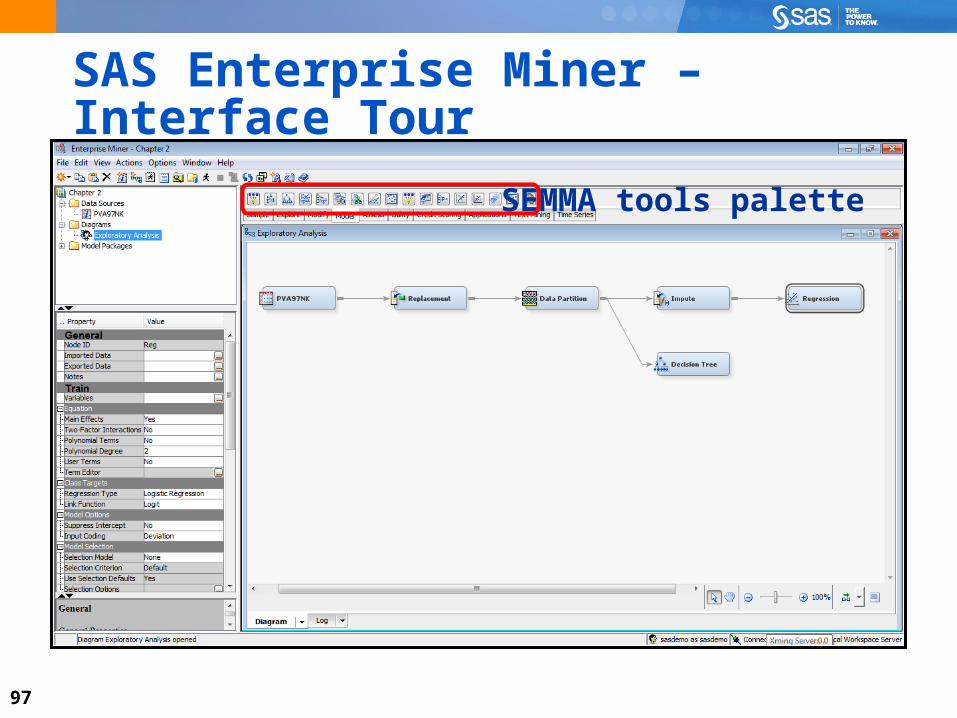
97
SAS Enterprise Miner – Interface Tour
SEMMA tools palette

98
Catalog Case StudyAnalysis Goal:
A mail-order catalog retailer wants to save money on mailing and increase revenue by targeting mailed catalogs to customers who are most likely to purchase in the future.
Data set: CATALOG2010
Number of rows: 48,356
Number of columns: 98
Contents: sales figures summarized across departments and quarterly totals for 5.5 years of sales
Targets: RESPOND (binary)
ORDERSIZE (continuous)

99
Catalog Case Study: BasicsThroughout this chapter, you work with data in SAS Enterprise Miner to perform exploratory analysis.
1. Import the CATALOG2010 data.
2. Identify the target variables.
3. Define and transform the variables for use in RFM analysis.
4. Perform graphical RFM analysis in SAS Enterprise Miner.
Later, you use the CATALOG2010 data for predictive modeling and scoring.

100
Accessing and Importing Data for ModelingFirst, get familiar with the data!
The data file is a SAS data set.
1.Create a project in SAS Enterprise Miner.
2.Create a diagram.
3.Locate and import the CATALOG2010 data.
4.Define characteristics of the data set, such as the variable roles and measurement levels.
5.Perform a basic exploratory analysis of the data.
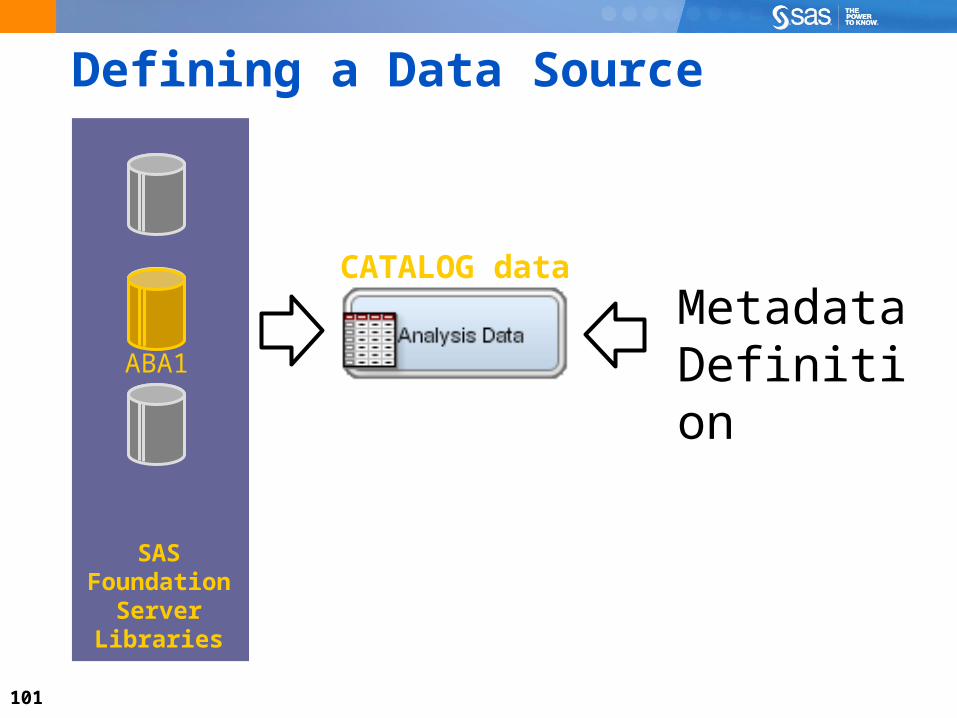
101
Defining a Data Source
SASFoundation
ServerLibraries
ABA1
CATALOG data
MetadataDefinition

102
Metadata DefinitionSelect a table.
Set the metadata information.
Three purposes for metadata: Define variable roles (such as input, target, or ID). Define measurement levels (such as binary, interval,
or nominal). Define table role (such as raw data, transactional data,
or scoring data).

103
Creating Projects and Diagrams in SAS Enterprise Miner
Catalog Case Study
Task: Create a project and a diagram in SAS Enterprise Miner.

104
Defining a Data Source
Catalog Case Study
Task: Define the CATALOG data source in SAS Enterprise Miner.

105
Defining Column Metadata
Catalog Case Study
Task: Define column metadata.

106
Changing the Sampling Defaults in the Explore Window and Exploring a Data Source
Catalog Case Study
Tasks: Change preference settings in the Explore window and explore variable associations.

107
Idea ExchangeConsider an academic retention example. Freshmen enter a university in the fall term, and some of them drop out before the second term begins. Your job is to try to predict whether a student is likely to drop out after the first term.
continued...

108
Idea Exchange What types of variables would you consider using to
assess this question? How does time factor into your data collection? Do
inferences about students five years ago apply to students today? How do changes in technology, university policies, and teaching trends affect your conclusions?
continued...

109
Idea Exchange As an administrator, do you have this information?
Could you obtain it? What types of data quality issues do you anticipate?
Are there any ethical considerations in accessing the information in your study?

110
Chapter 2: Basics of Business Analytics
2.1 Overview of Techniques
2.2 Data Management
2.3 Data Difficulties
2.4 SAS Enterprise Miner: A Primer
2.5 Honest Assessment2.5 Honest Assessment
2.6 Methodology
2.7 Recommended Reading

111
Objectives Explain the characteristics of a good predictive model. Describe data splitting. Discuss the advantages of using honest assessment
to evaluate a model and obtain the model with the best prediction.

112
Predictive Modeling Implementation Model Selection and Comparison
– Which model gives the best prediction? Decision/Allocation Rule
– What actions should be taken on new cases? Deployment
– How can the predictions be applied to new cases?
...
113
Predictive Modeling Implementation Model Selection and Comparison
– Which model gives the best prediction? Decision/Allocation Rule
– What actions should be taken on new cases? Deployment
– How can the predictions be applied to new cases?

114
Getting the “Best” Prediction: Fool’s Gold
My model fits thetraining data perfectly...
I’ve struck it rich!

115
2.05 PollThe best model is a model that does a good job of predicting your modeling data.
Yes
No
116
2.05 Poll – Correct AnswerThe best model is a model that does a good job of predicting your modeling data.
Yes
No

117
Model Complexity
...
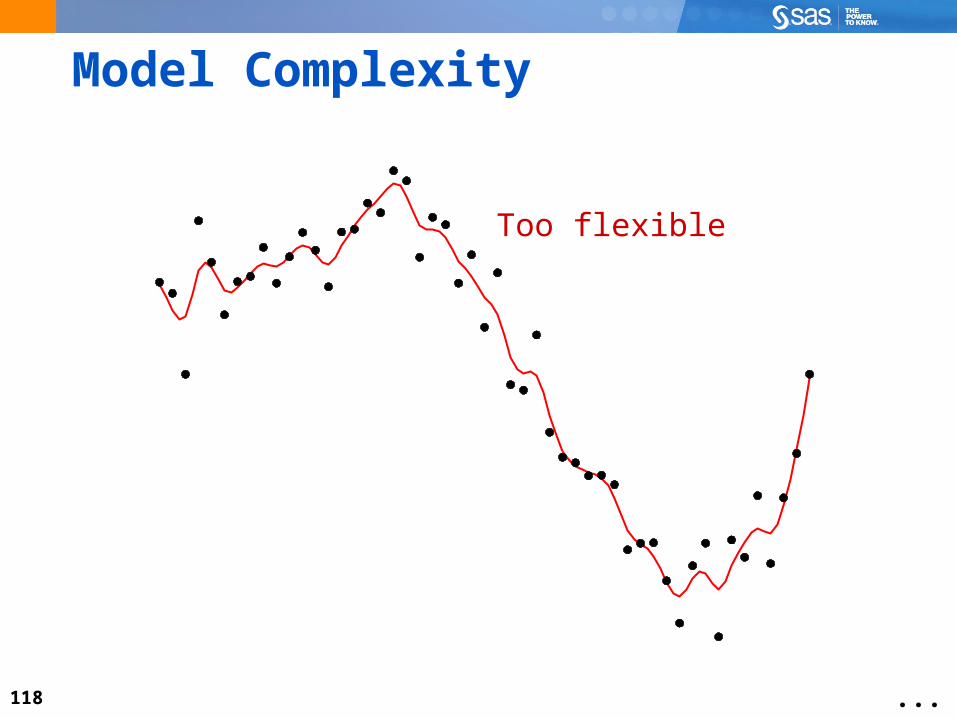
118
Model Complexity
Too flexible
...
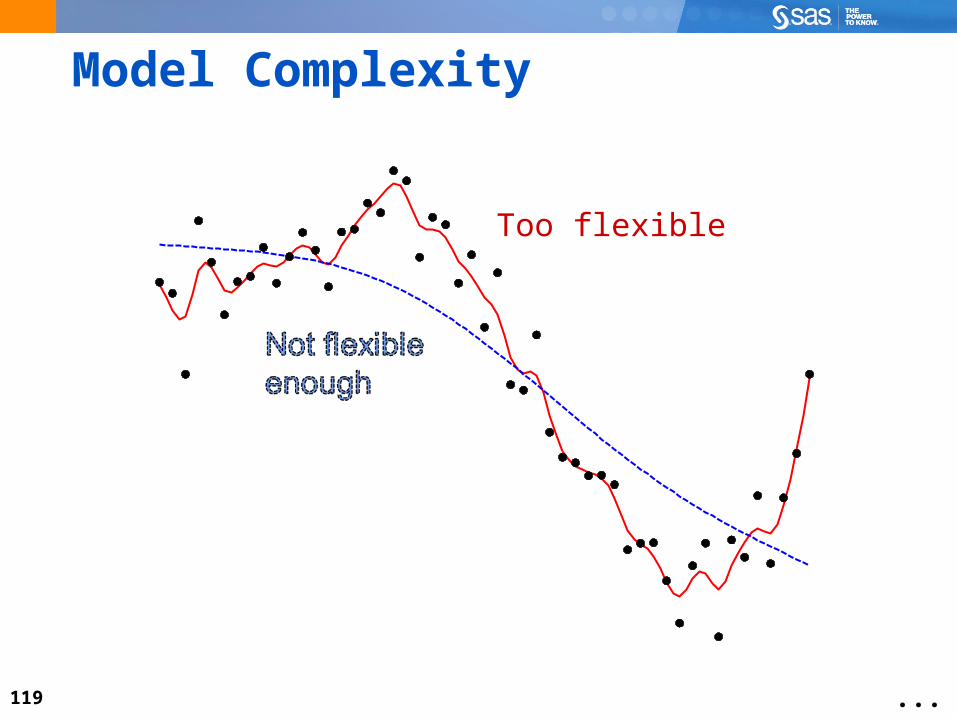
119
Model Complexity
Too flexible
...

120
Model Complexity
Too flexible
Just right

121
Data Splitting and Honest Assessment
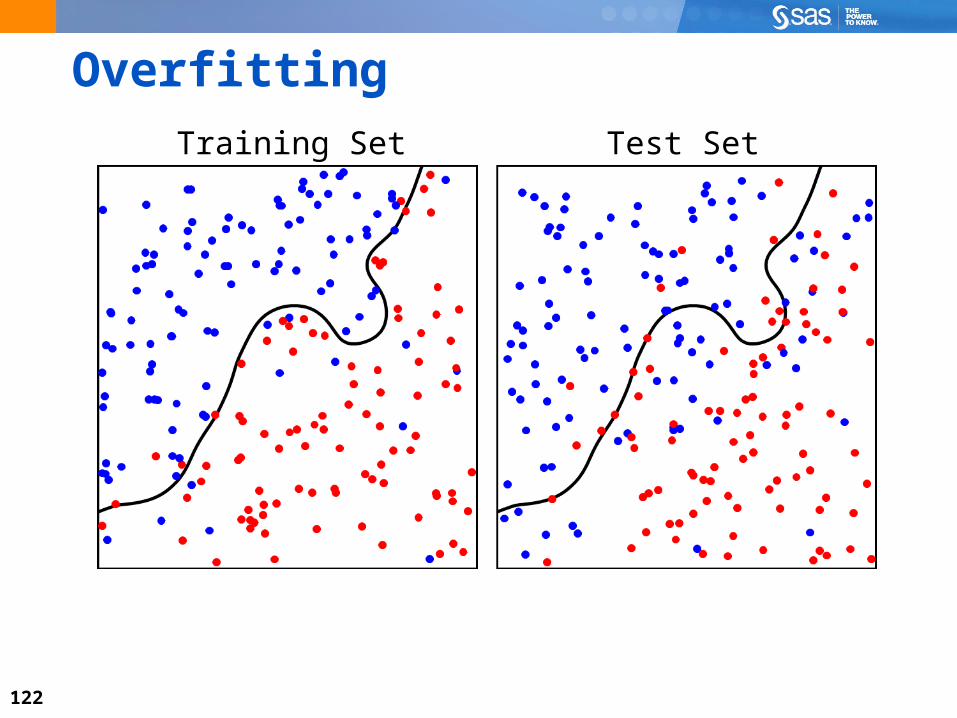
122
Overfitting
Training Set Test Set
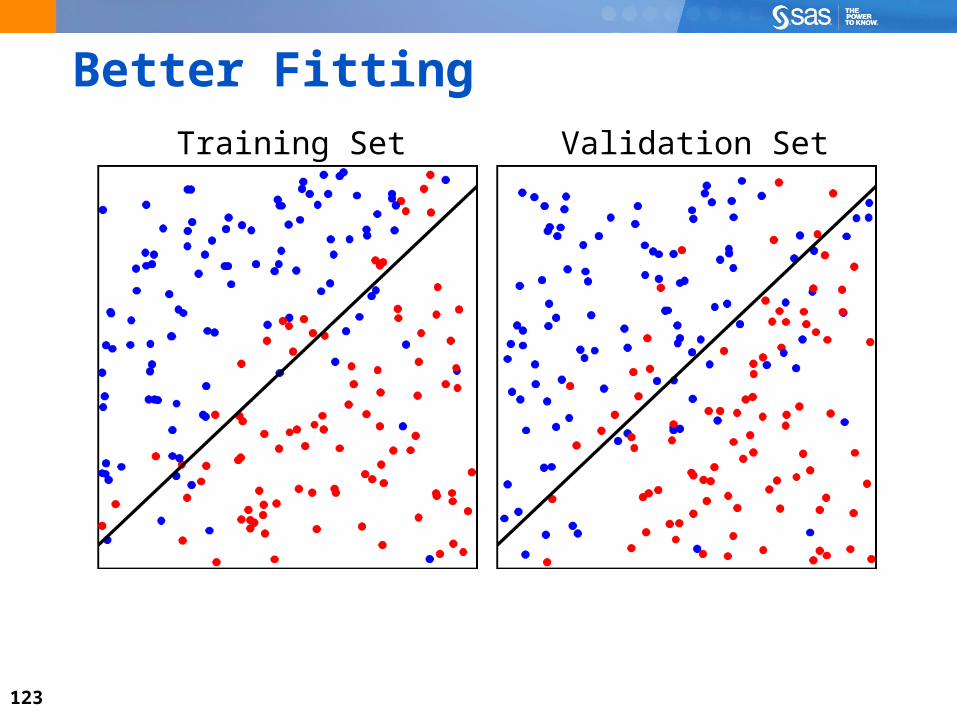
123
Better Fitting
Training Set Validation Set

124
Predictive Modeling Implementation Model Selection and Comparison
– Which model gives the best prediction? Decision/Allocation Rule
– What actions should be taken on new cases? Deployment
– How can the predictions be applied to new cases?
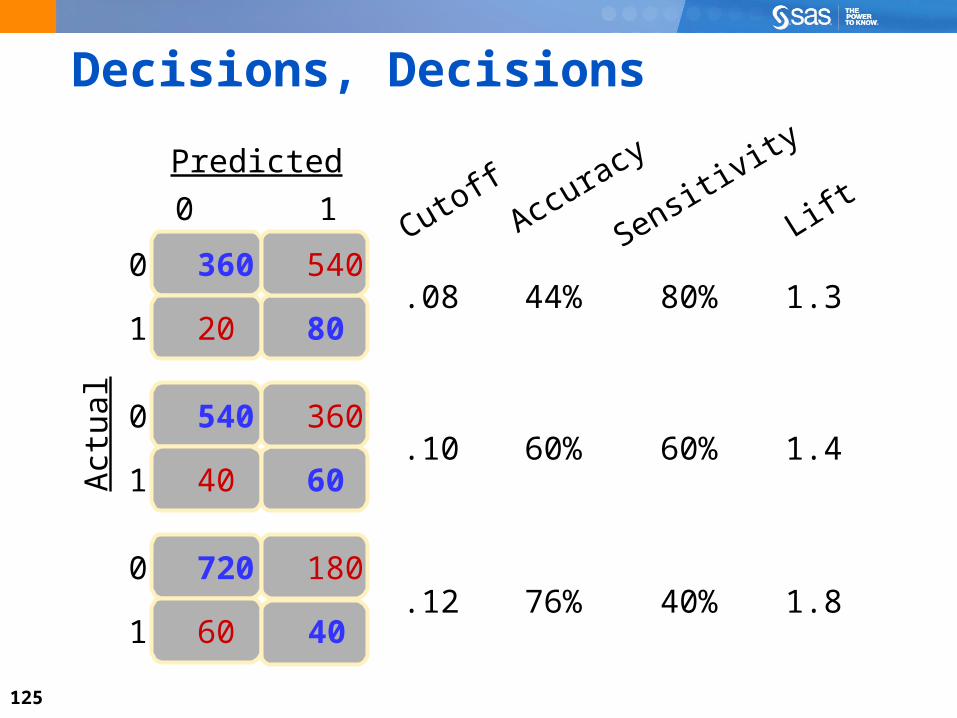
125
Decisions, Decisions
540
40
360
60
360
20
540
80
0
1
0 1
720
60
180
40
0
1
0
1
Predicted
Act
ual
CutoffAccuracy
.08
.10
.12
44%
60%
76%
Sensitivity
Lift
80%
60%
40%
1.3
1.4
1.8

126
Misclassification Costs
True Neg
False Pos
False Neg
True Pos
0
1
0 1
Predicted Class
Act
ual 0 1
9 0
OK
Fraud
Accept Deny
Action

127
Predictive Modeling Implementation Model Selection and Comparison
– Which model gives the best prediction? Decision/Allocation Rule
– What actions should be taken on new cases? Deployment
– How can the predictions be applied to new cases?
128
Scoring
Model Development
Model Deployment

129
Scoring Recipe The model results in
a formula or rules. The data requires
modifications.– Derived inputs– Transformations– Missing value
imputation
The scoring code is deployed.– To score, you do not
rerun the algorithm; apply score code (equations) obtained from the final model to the scoring data.
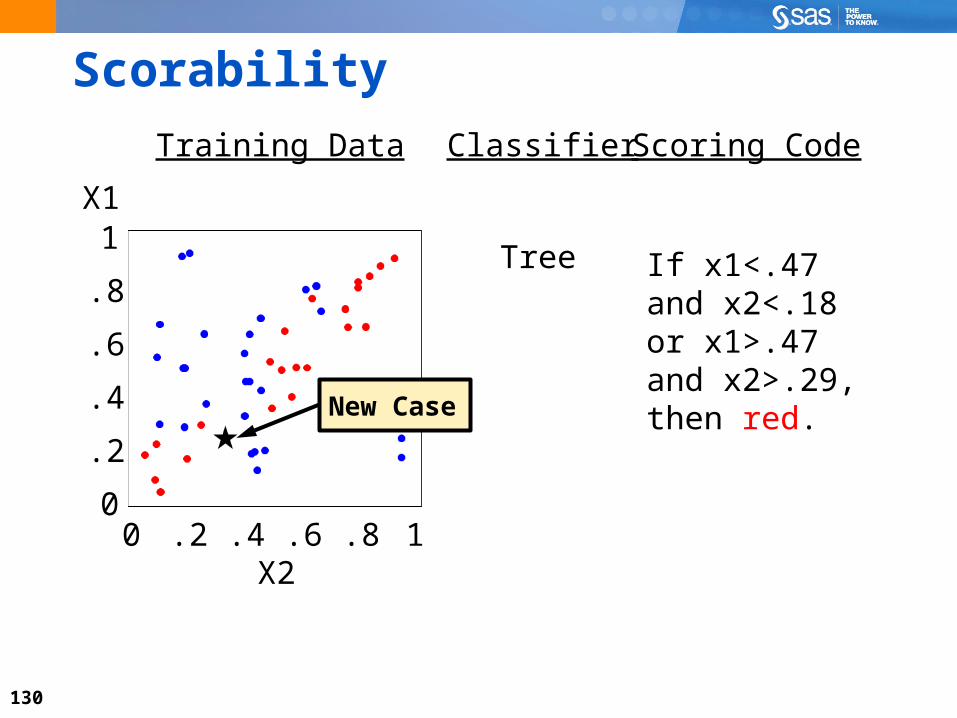
130
Scorability
X1
0
.2
.4
.6
.8
1
X20 .2 .4 .6 .8 1
Scoring CodeClassifier
If x1<.47and x2<.18or x1>.47and x2>.29,then red.
Tree
Training Data
New Case
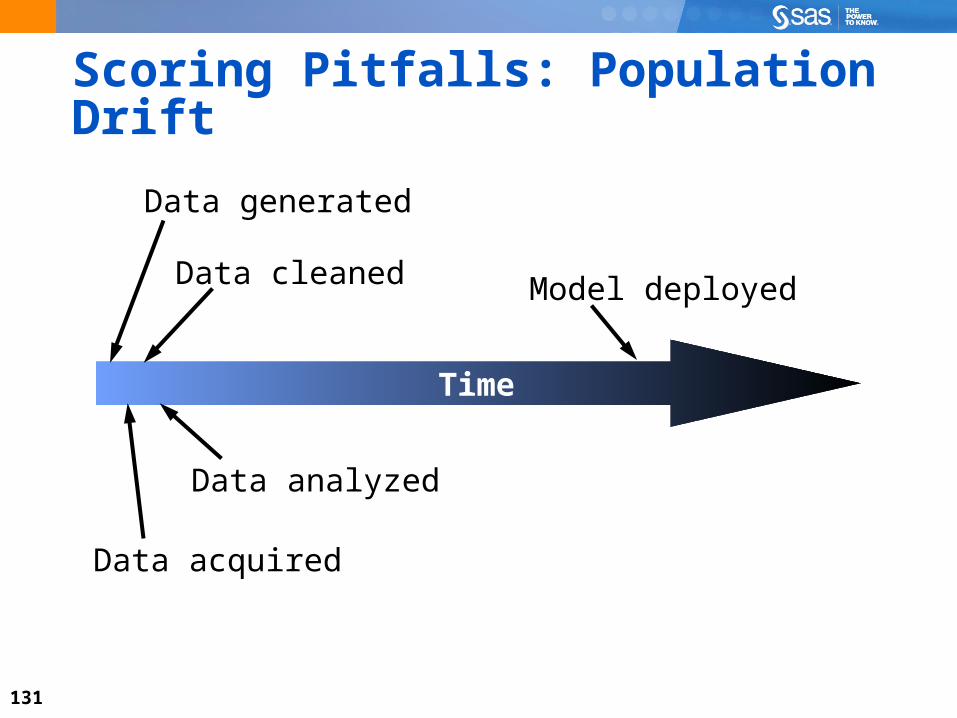
131
Scoring Pitfalls: Population Drift
Data acquired
Data cleaned
Data analyzed
Model deployed
Data generated
Time

132
The Secret to Better Predictions
OK
Fraud
Transaction Amt.
Tim
e of
Day
...
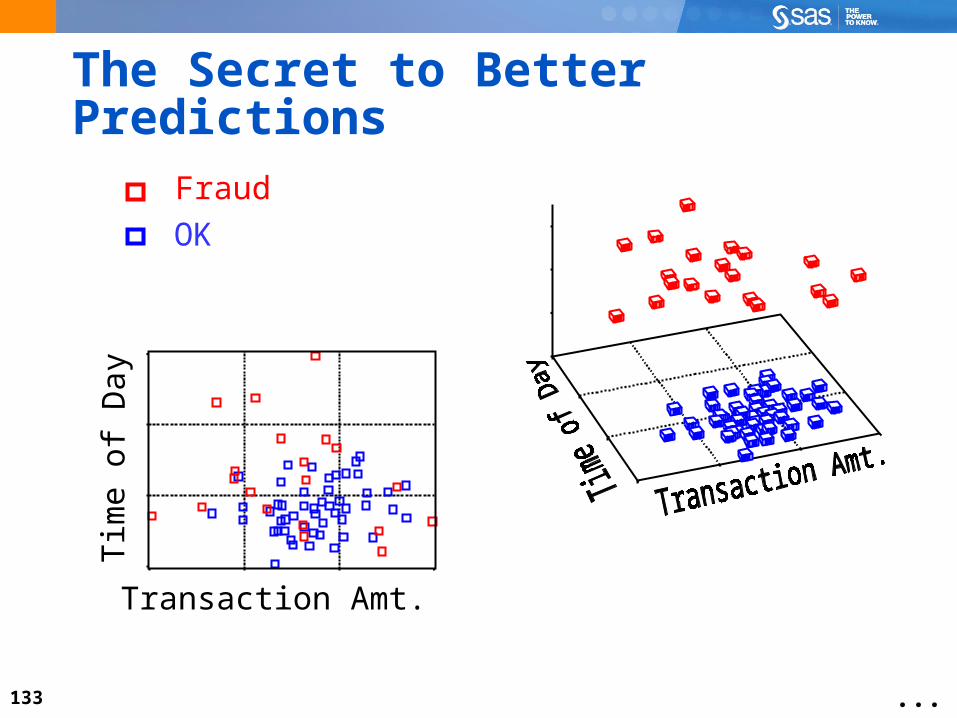
133
The Secret to Better Predictions
OK
Fraud
Transaction Amt.
Tim
e of
Day
...
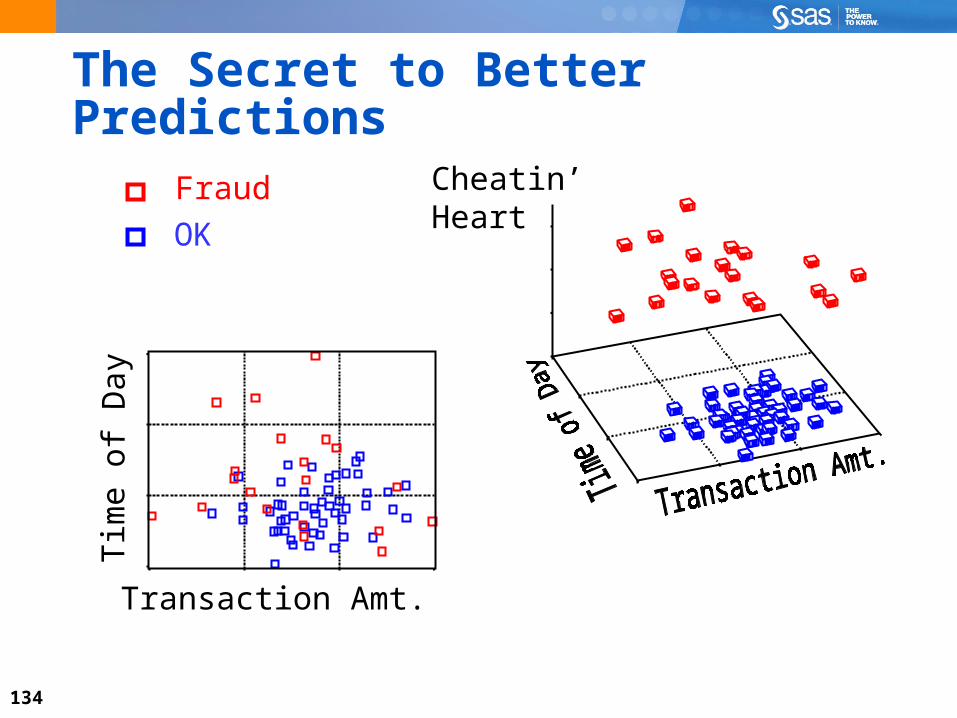
134
The Secret to Better Predictions
OK
Fraud
Transaction Amt.
Tim
e of
Day
Cheatin’Heart

135
Idea ExchangeThink of everything that you have done in the past week. What transactions or actions created data? For example, point-of-sale transactions, Internet activity, surveillance, and questionnaires are all data collection avenues that many people encounter daily. How do you think that the data about you will be used? How could models be deployed that use data about
you?

136
Chapter 2: Basics of Business Analytics
2.1 Overview of Techniques
2.2 Data Management
2.3 Data Difficulties
2.4 SAS Enterprise Miner: A Primer
2.5 Honest Assessment
2.6 Methodology2.6 Methodology
2.7 Recommended Reading

137
Objectives Describe a methodology for implementing business
analytics through data mining. Discuss each of the steps, with examples, in the
methodology. Create a project and diagram in SAS Enterprise Miner.
138
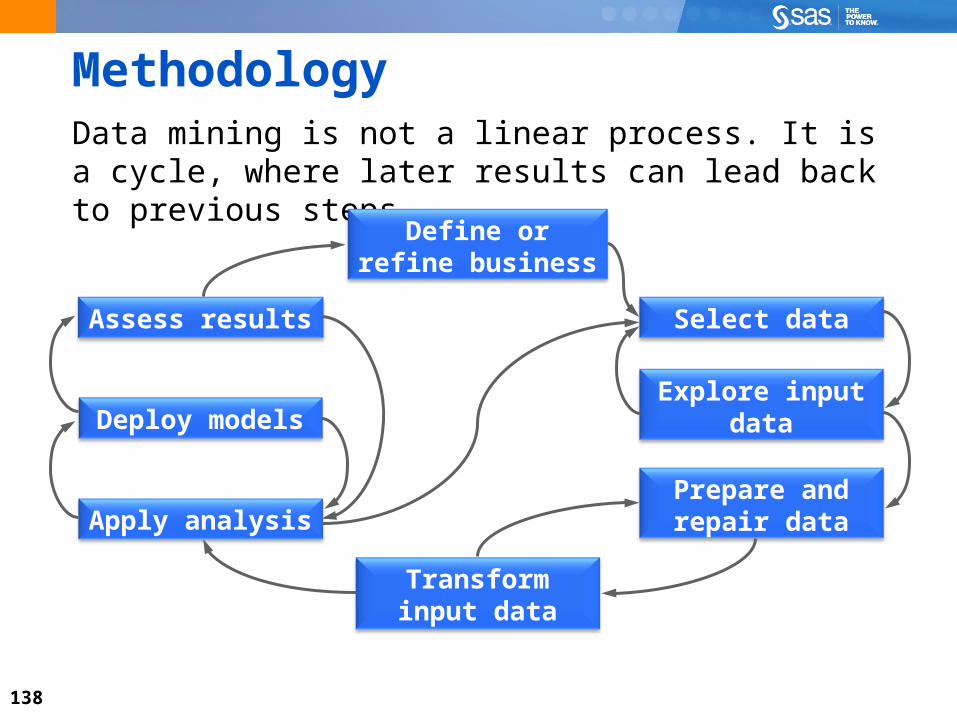
MethodologyData mining is not a linear process. It is a cycle, where later results can lead back to previous steps.
Select data
Define or refine business objective
Assess results
Deploy modelsExplore input
data
Prepare and repair data
Transform input data
Apply analysis

139
Why Have a Methodology? To avoid learning things that are not true To avoid learning things that are not useful
– results that arise from past marketing decisions– results that you already know– results that you already should know– results that you are not allowed to use
To create stable models To avoid making the mistakes that you made in the
past To develop useful tips from what you learned

140
Methodology1. Define the business objective and state it as a
data mining task.
Select data
Define or refine business objective
Assess results
Deploy modelsExplore input
data
Prepare and repair data
Transform input data
Apply analysis

141
1) Define the Business Objective Improve the response rate for a direct
marketing campaign. Increase the average order size. Determine what drives customer acquisition. Forecast the size of the customer base in the future. Choose the right message for the right groups of
customers. Target a marketing campaign to maximize incremental
value. Recommend the next, best product for existing customers. Segment customers by behavior.
A lot of good statistical analysis is directed at solving the wrong business problem.

142
Define the Business GoalExample: Who is the yogurt lover? What is a yogurt lover? One answer prints coupons
at the cash register. Another answer mails coupons
to people’s homes. Another results in advertising.
143
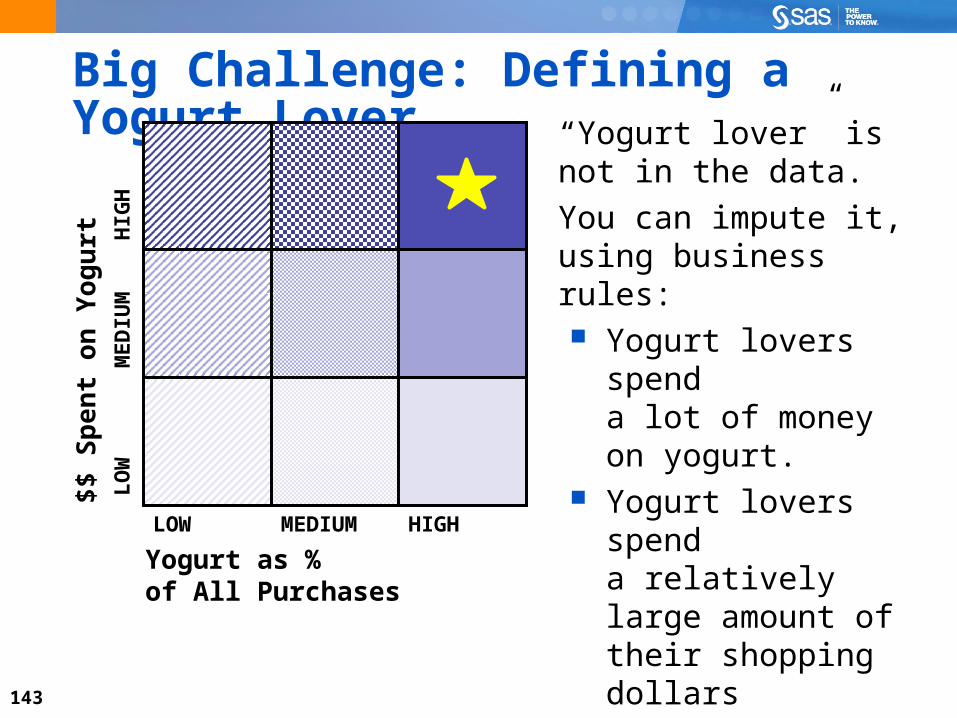
Big Challenge: Defining a Yogurt Lover
LOW MEDIUM HIGH
LO
WM
ED
IUM
HIG
H
$$
Sp
en
t o
n Y
og
urt
Yogurt as %of All Purchases
“Yogurt lover” is not in the data.
You can impute it, using business rules: Yogurt lovers spend
a lot of money on yogurt.
Yogurt lovers spend a relatively large amount of their shopping dollars on yogurt.

144
Next Challenge: Profile the Yogurt LoverYou have identified a segment of customers that you believe are yogurt lovers.
But who are they? How would I know them in the store? Identify them by demographic data. Identify them by other things that they purchase (for
example, yogurt lovers are people who buy nutrition bars and sports drinks).
What action can I take? Set up “yogurt-lover-attracting” displays.

145
Idea ExchangeIf a customer is identified as a yogurt lover, what action should you take? Should you give yogurt coupons, even though these individuals buy yogurt anyway? Is there a cross-sell opportunity? Is there an opportunity to identify potential yogurt lovers? What would you do?

146
Profiling in the Extreme: Best BuyUsing analytical methodology, electronics retailer Best Buy discovered that a small percentage of customers accounted for a large percentage of revenue.
Over the past several years, the company has adopted a customer-centric approach to store design and flow, staffing, and even corporate acquisitions such as the Geek Squad support team.
The company’s largest competitor has gone bankrupt while Best Buy has seen growth in market share.
See Gulati (2010)

147
Define the Business ObjectiveWhat Is the business objective?
Example: Telco Churn
Initial problem: Assign a churn score to all customers. Recent customers with little call history Telephones? Individuals? Families? Voluntary churn versus involuntary churn
How will the results be used?
Better objective: By September 24, provide a list of the 10,000 elite customers who are most likely to churn in October.
The new objective is actionable.
148
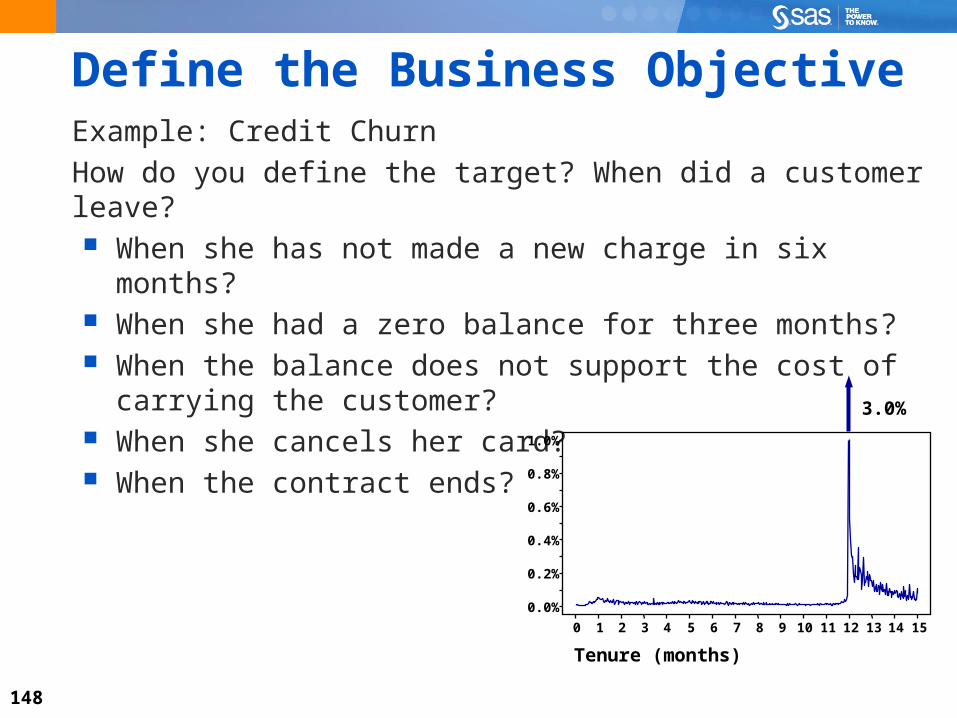
Define the Business ObjectiveExample: Credit Churn
How do you define the target? When did a customer leave? When she has not made a new charge in six months? When she had a zero balance for three months? When the balance does not support the cost of carrying
the customer? When she cancels her card? When the contract ends?
Tenure (months)
0.0%
0.2%
0.4%
0.6%
0.8%
1.0%
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
3.0%

149
Translate Business Objectives into Data Mining TasksDo you already know the answer?
In supervised data mining, the data has examples of what you are looking for, such as the following: customers who responded in the past customers who stopped transactions identified as fraud
In unsupervised data mining, you are looking for new patterns, associations, and ideas.

150
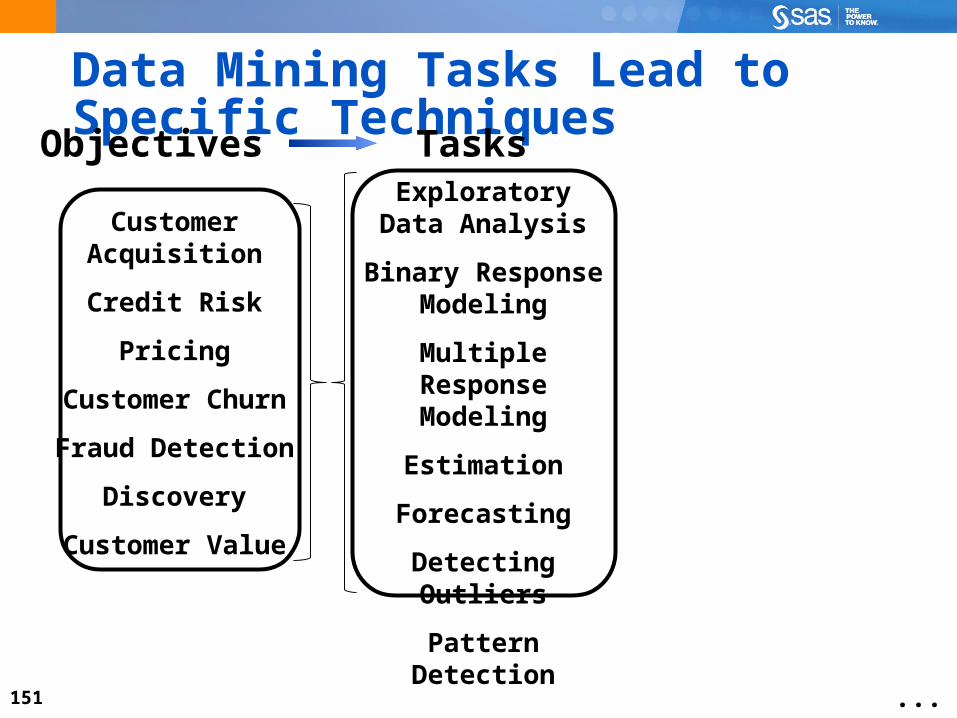
Data Mining Tasks Lead to Specific Techniques
Customer Acquisition
Credit Risk
Pricing
Customer Churn
Fraud Detection
Discovery
Customer Value
Objectives
...
151
Data Mining Tasks Lead to Specific Techniques
Exploratory Data Analysis
Binary Response Modeling
Multiple Response Modeling
Estimation
Forecasting
Detecting Outliers
Pattern Detection
Customer Acquisition
Credit Risk
Pricing
Customer Churn
Fraud Detection
Discovery
Customer Value
TasksObjectives
...
152
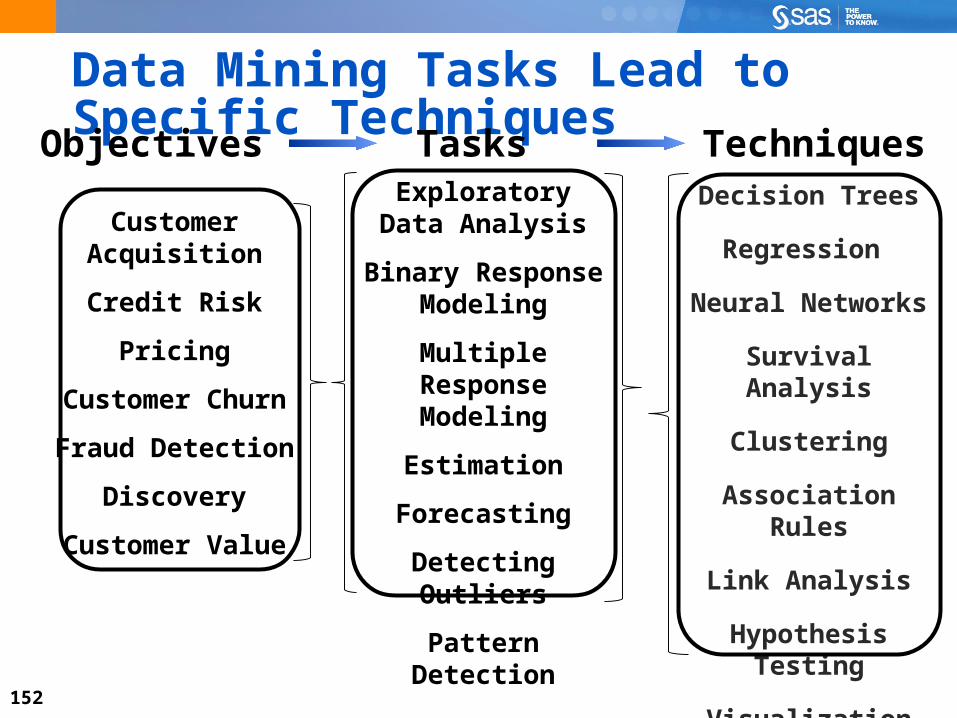
Data Mining Tasks Lead to Specific Techniques
Decision Trees
Regression
Neural Networks
Survival Analysis
Clustering
Association Rules
Link Analysis
Hypothesis Testing
Visualization
Exploratory Data Analysis
Binary Response Modeling
Multiple Response Modeling
Estimation
Forecasting
Detecting Outliers
Pattern Detection
Customer Acquisition
Credit Risk
Pricing
Customer Churn
Fraud Detection
Discovery
Customer Value
TasksObjectives Techniques

153
Data Analysis Is Pattern DetectionPatterns might not represent any underlying rule.
Some patterns reflect some underlying reality. The party that holds the White House tends to
lose seats in Congress during off-year elections.
Others do not. When the American League wins the World Series
in Major League Baseball, Republicans take the White House.
Stars cluster in constellations.
Sometimes, it is difficult to tell without analysis. In U.S. presidential contests, the taller candidate
usually wins.

154
Example: Maximizing DonationsExample from the KDD Cup, a data mining competition associated with the KDD Conference (www.sigkdd.org): Purpose: Maximizing profit for a charity fundraising
campaign Tested on actual results from mailing (using data withheld
from competitors)
Competitors took multiple approaches to the modeling: Modeling who will respond Modeling how much people will give Perhaps more esoteric approaches
However, the top three winners all took the same approach (although they used different techniques, methods, and software).
155
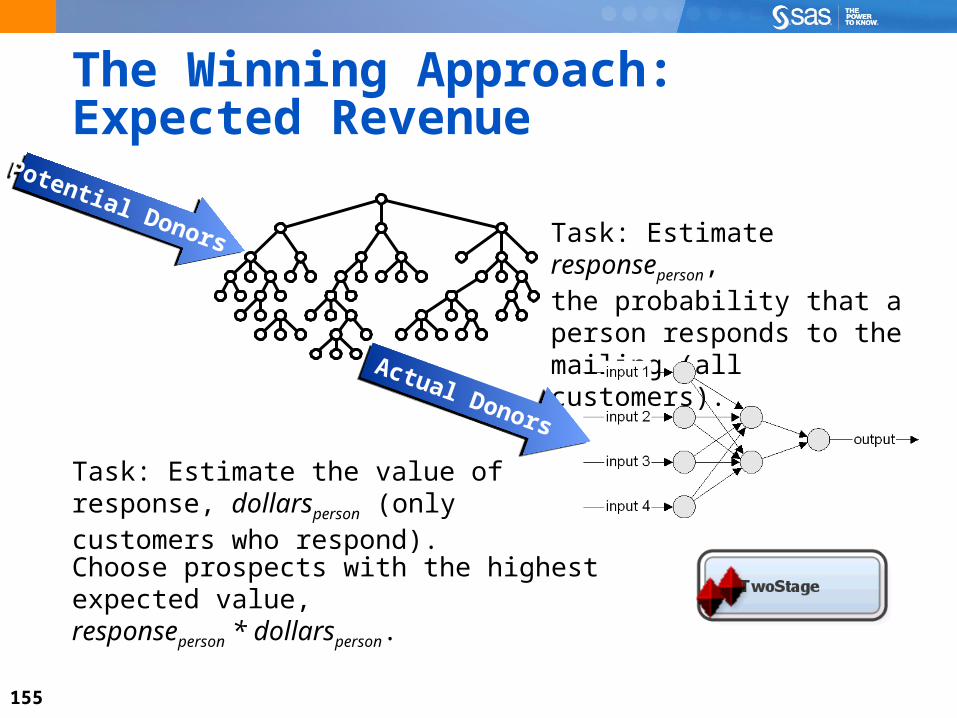
The Winning Approach:Expected Revenue
Task: Estimate responseperson, the probability that a person responds to the mailing (all customers).
Task: Estimate the value of response, dollarsperson (only customers who respond).
Choose prospects with the highest expected value,responseperson * dollarsperson.
Actual Donors
Actual Donors
Potential Donors
Potential Donors

156
An Unexpected PatternAn unexpected pattern suggests an approach.
When people give money frequently, they tend to donate less money each time. In most business applications, as people take an action
more often, they spend more money. Donors to a charity are different.
This suggests that potential donors go through a two-step process: Shall I respond to this mailing? How much money should I give
this time?
Modeling can follow the same logic.
157
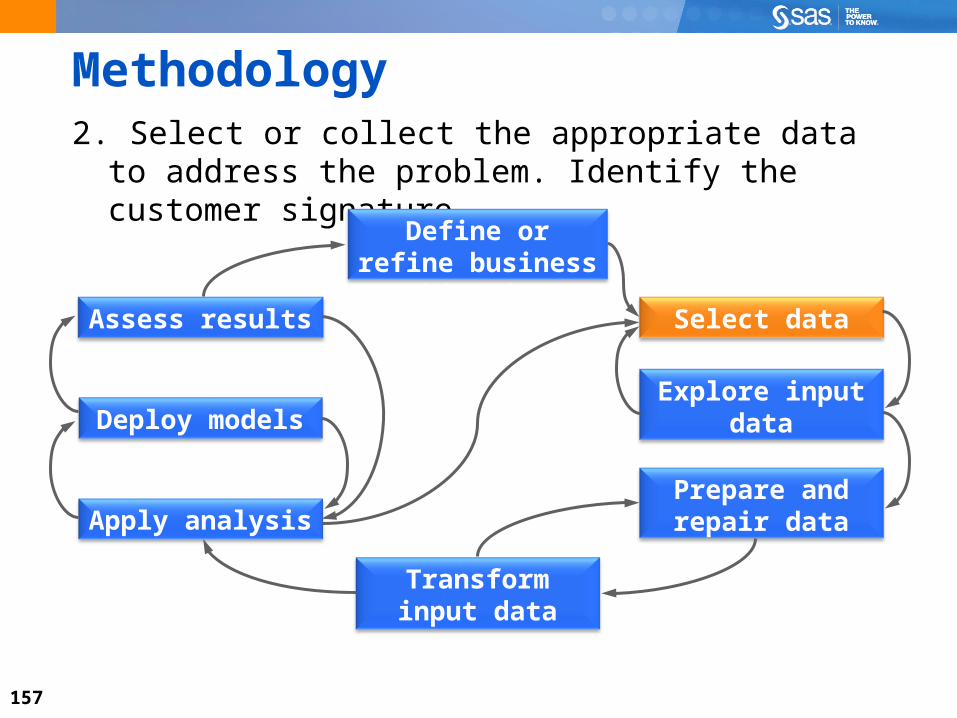
Methodology2. Select or collect the appropriate data to address the
problem. Identify the customer signature.
Select data
Define or refine business objective
Assess results
Deploy modelsExplore input
data
Prepare and repair data
Transform input data
Apply analysis

158
2) Select Appropriate Data What is available? What is the right level of granularity? How much data is needed? How much history is required? How many variables should be used? What must the data contain?
Assemble results into customer signatures.

159
Representativeness of the Training SampleThe model set might not reflect the relevant population. Customers differ from prospects. Survey responders differ from non-responders. People who read e-mail differ from people who do not
read e-mail. Customers who started three
years ago might differ from customers who started three months ago.
People with land lines differ from those without.

160
Availability of Relevant Data Elevated printing defect rates might be due to humidity, but that information is not in press run records.
Poor coverage might be the number one reason for wireless subscribers canceling their subscriptions, but data about dropped calls is not in billing data.
Customers might already have potential cross-sell products from other companies, but that information is not available internally.

161
Types of Attributes in DataReadily Supported Binary Categorical (nominal) Numeric (interval) Date and time
Require More Work Text Image Video Links

162
Idea ExchangeSuppose that you were in charge of a charity similar to the KDD example above. What type of data are you likely to have available before beginning the project? Is there additional data that you would need?
Do you have to purchase the data, or is it publicly available for free? How could you make the best use of a limited budget to acquire high quality data about individual donation patterns?
163
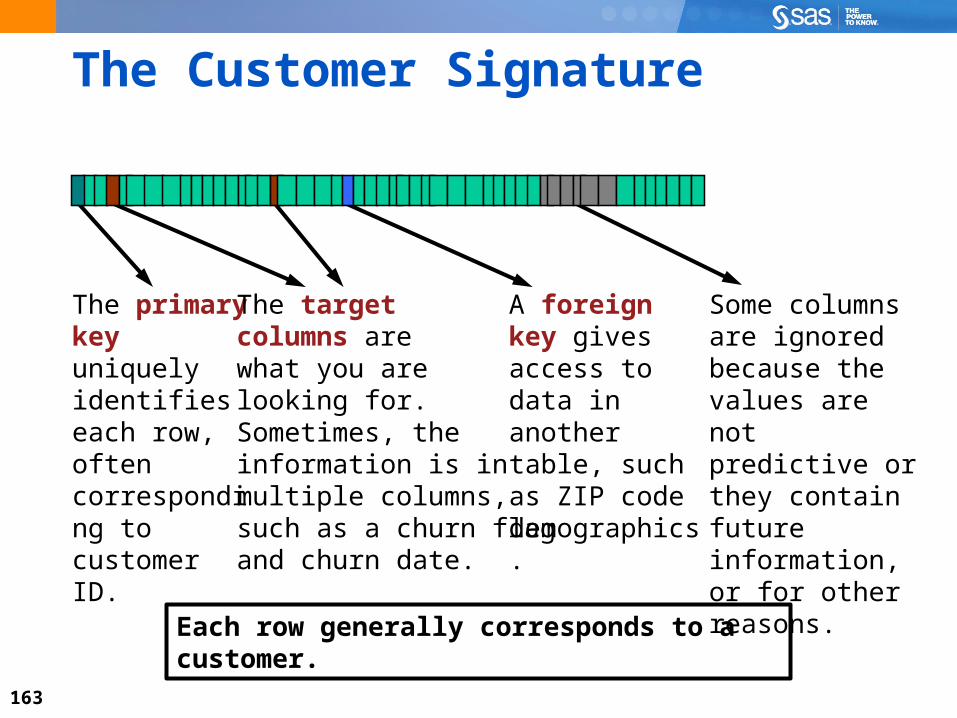
The Customer Signature
The primary key uniquely identifies each row, often corresponding to customer ID.
A foreign key gives access to data in another table, such as ZIP code demographics.
The targetcolumns arewhat you arelooking for.Sometimes, theinformation is inmultiple columns, such as a churn flagand churn date.
Some columns are ignored because the values are not predictive or they contain future information, or for other reasons.
Each row generally corresponds to a customer.

164
Data Assembly Operations
Pivoting
Aggregation
Table lookup
Summarizationof values from data
Derivation ofnew variables
Copying
165
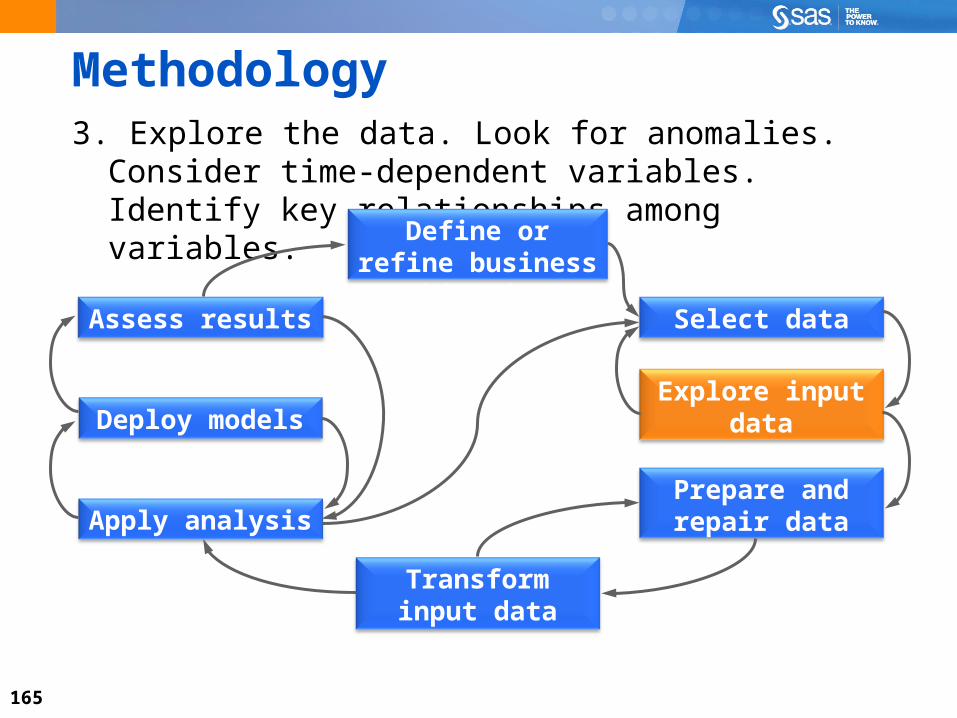
Methodology3. Explore the data. Look for anomalies. Consider time-
dependent variables. Identify key relationships among variables.
Select data
Define or refine business objective
Assess results
Deploy modelsExplore input
data
Prepare and repair data
Transform input data
Apply analysis

166
3) Explore the DataExamine distributions. Study histograms. Think about extreme values. Notice the prevalence of missing values.
Compare values with descriptions.
Validate assumptions.
Ask many questions.

167
Ask Many Questions Why were some customers active for 31 days in February, but
none were active for more than 28 days in January? How do some retail card holders spend more than $100,000
in a week in a grocery store? Why were so many customers born in 1911? Are they really
that old? Why do Safari users never make second purchases? What does it mean when the contract begin date is after the
contract end date? Why are there negative numbers in the sale price field? How can active customers have a non-null value in the
cancellation reason code field?
168
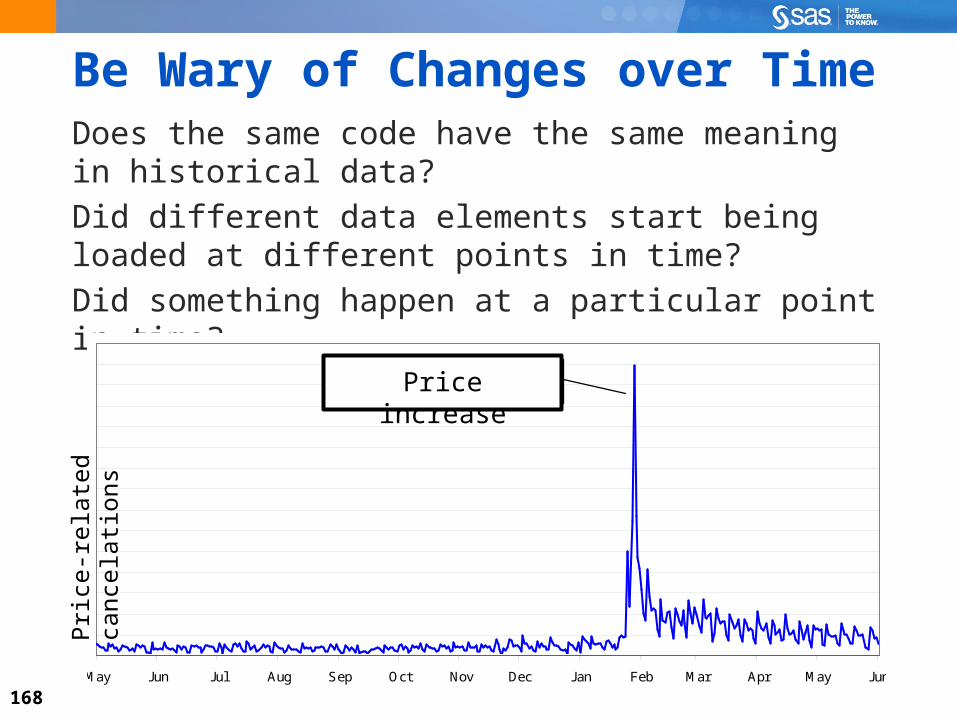
Be Wary of Changes over TimeDoes the same code have the same meaning in historical data?
Did different data elements start being loaded at different points in time?
Did something happen at a particular point in time?
May Jun Jul Aug Sep Oct Nov Dec Jan Feb Mar Apr May Jun
price complaint stops
Pric
e-re
late
d ca
ncel
atio
ns Price increase
169
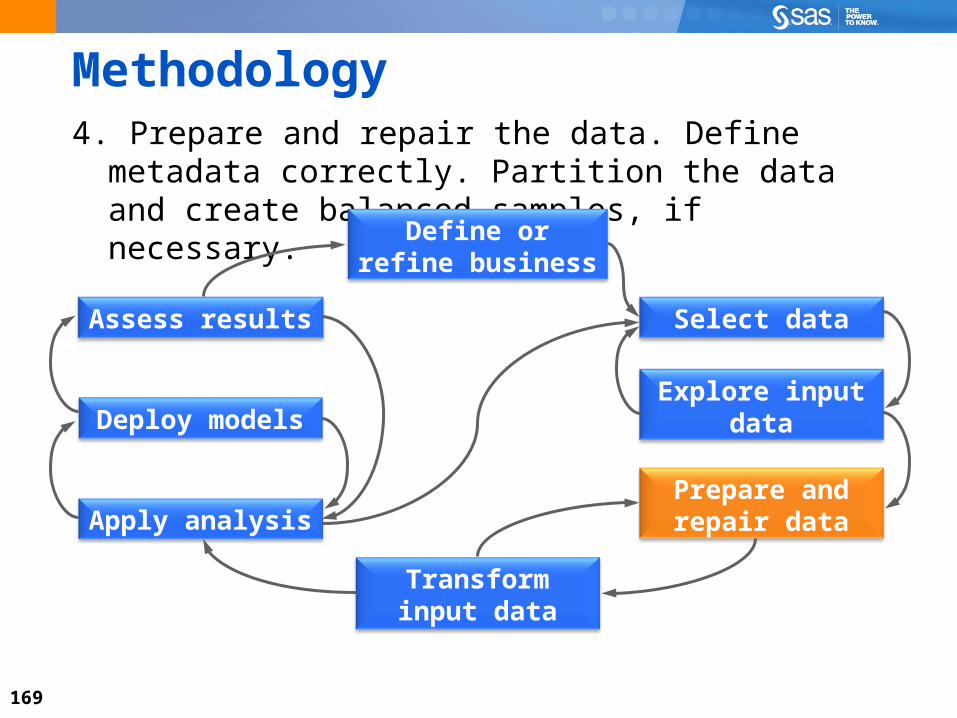
Methodology4. Prepare and repair the data. Define metadata correctly.
Partition the data and create balanced samples, if necessary.
Select data
Define or refine business objective
Assess results
Deploy modelsExplore input
data
Prepare and repair data
Transform input data
Apply analysis

170
4) Prepare and Repair the Data Set up a proper temporal relationship
between the target variable and inputs. Create a balanced sample, if possible. Include multiple time frames if necessary. Split the data into training, validation, and (optionally)
test data sets.

171
Temporal Relationship: Prediction or Profiling?The same techniques work for both.
In a predictive model, values of explanatoryvariables are from an earlier time frame than the target variable.
In a profiling model, the explanatory variables and the target variable might all be from the same time frame.
Earlier
Later
Same Time Frame

172
Balancing the Input Data SetA very accurate model simply predicts that no one wants a brokerage account: 98.8% accurate 1.2% error rate
This is useless for differentiating among customers.
Distribution of Brokerage Target Variable
228,926
2,355
0 50,000 100,000 150,000 200,000 250,000
Brokerage = "N"
Brokerage = "Y"
173
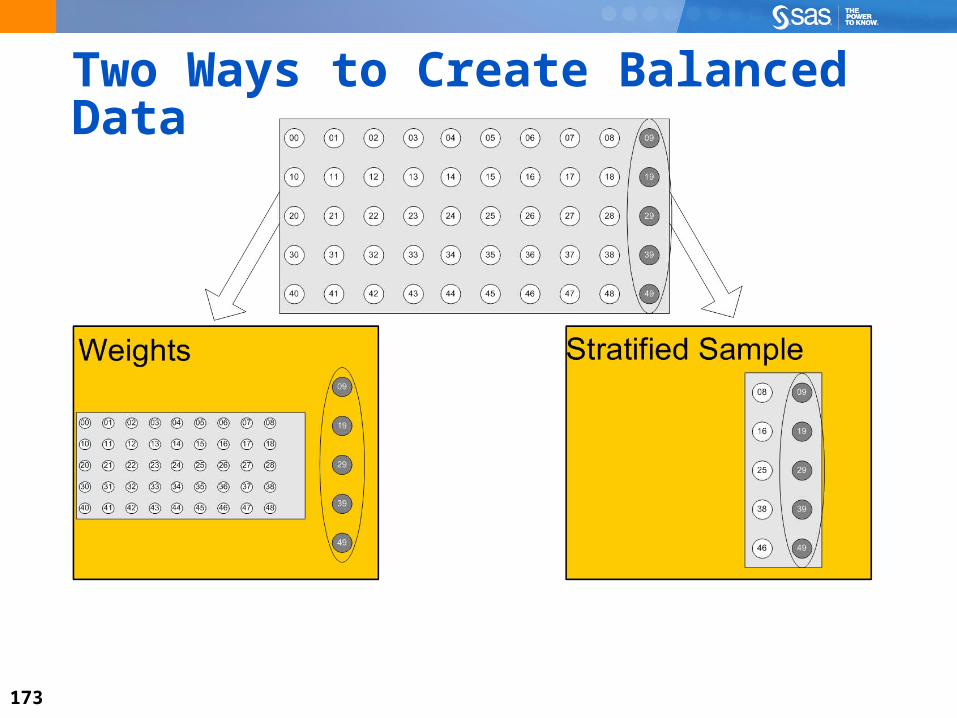
Two Ways to Create Balanced Data
174
Data Splitting and Validation
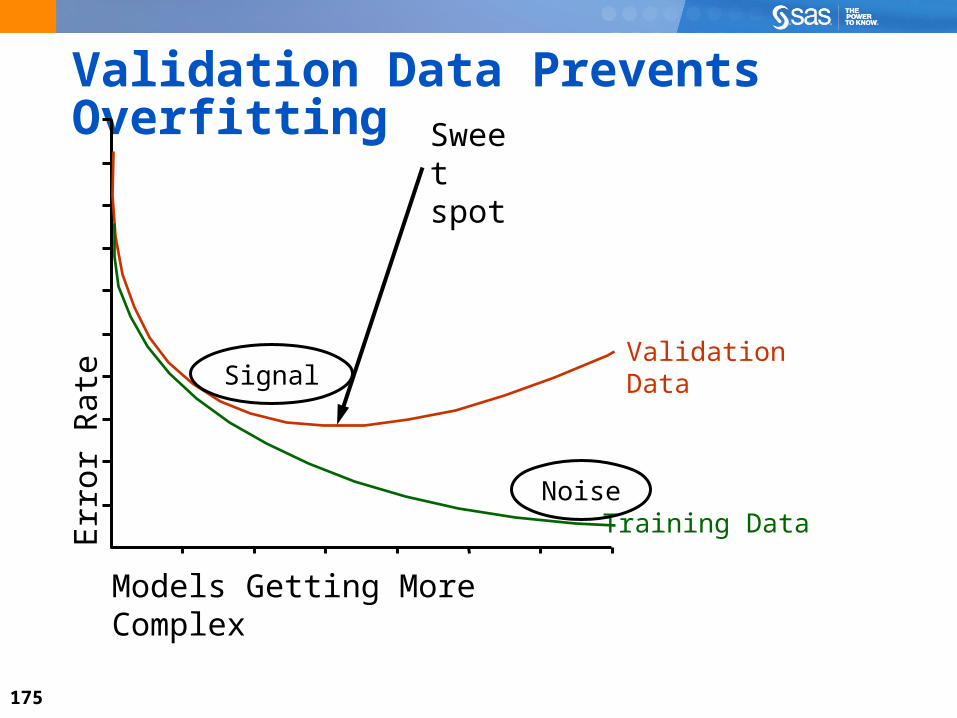
Improving the model causes the error rate to decline on the data used to build it. At the same time, the model becomes more complex.
Err
or R
ate
Models Getting More Complex
175
Validation Data Prevents Overfitting
Training Data
Validation DataSignal
Noise
Err
or R
ate
Models Getting More Complex
Sweet spot

176
Partitioning the Input Data SetUse the training set to find patterns and create an initial set of candidate models.
Use the validation set to select the best model from the candidate set of models.
Use the test set to measure performance of the selected model on unseen data. The test set can be an out-of-time sample of the data, if necessary.
Partitioning data is an allowable luxury because data mining assumes a large amount of data.
Test sets do not help select the final model; they only provide an estimate of the model’s effectiveness in the population. Test sets are not always used.
TrainingTraining
ValidationValidation
TestTest

177
Fix Problems with the DataData imperfectly describes the features of the real world. Data might be missing or empty. Samples might not be representative. Categorical variables might have too many values. Numeric variables might have unusual distributions
and outliers. Meanings can change over time. Data might be coded inconsistently.

178
No Easy Fix for Missing ValuesThrow out the records with missing values? No. This creates a bias for the sample.
Replace missing values with a “special” value (-99)? No. This resembles any other value to a data mining algorithm.
Replace with some “typical” value? Maybe. Replacement with the mean, median, or mode changes
the distribution, but predictions might be fine.
Impute a value? (Imputed values should be flagged.) Maybe. Use distribution of values to randomly choose a value. Maybe. Model the imputed value using some technique.
Use data mining techniques that can handle missing values? Yes. One of these, decision trees, is discussed.
Partition records and build multiple models? Yes. This action is possible when data is missing for a
canonical reason, such as insufficient history.
179
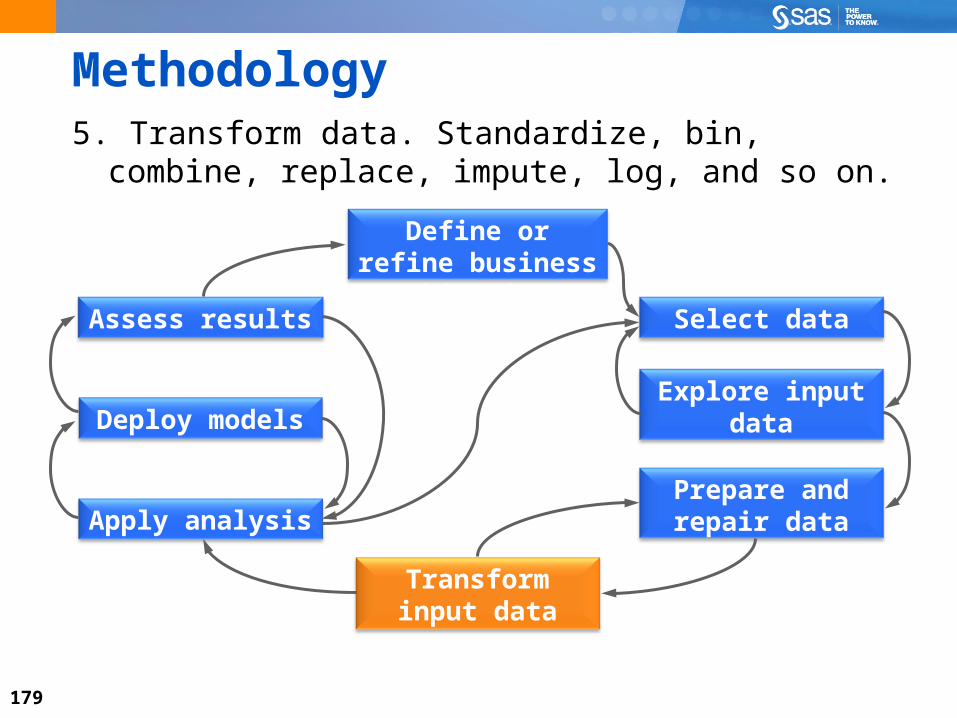
Methodology5. Transform data. Standardize, bin, combine, replace,
impute, log, and so on.
Select data
Define or refine business objective
Assess results
Deploy modelsExplore input
data
Prepare and repair data
Transform input data
Apply analysis

180
5) Transform Data Standardize values into z-scores. Change counts into percentages. Remove outliers. Capture trends with ratios, differences, or beta values. Combine variables to bring information to the surface. Replace categorical variables with some numeric
function of the categorical values. Impute missing values. Transform using mathematical functions, such as logs. Translate dates to durations.
Example: Body Mass Index (kg/m2) is a better predictor of diabetes than either variable separately.

181
A Selection of TransformationsStandardize numeric values. All numeric values are replaced by the notion of “how
far is this value from the average?” Conceptually, all numeric values are in the same range.
(The actual range differs, but the meaning is the same.) Although it sometimes has no effect on the results
(such as for decision trees and regression), it never produces worse results.
Standardization is so useful that it is often built into SAS Enterprise Miner modeling nodes.

182
A Selection of Transformations“Stretching” and “squishing” transformations Log, reciprocal, and square root are examples.
Replace categorical values with appropriate numeric values. Many techniques work better with numeric values than
with categorical values. Historical projections (such as handset churn rate or
penetration by ZIP code) are particularly useful.
183
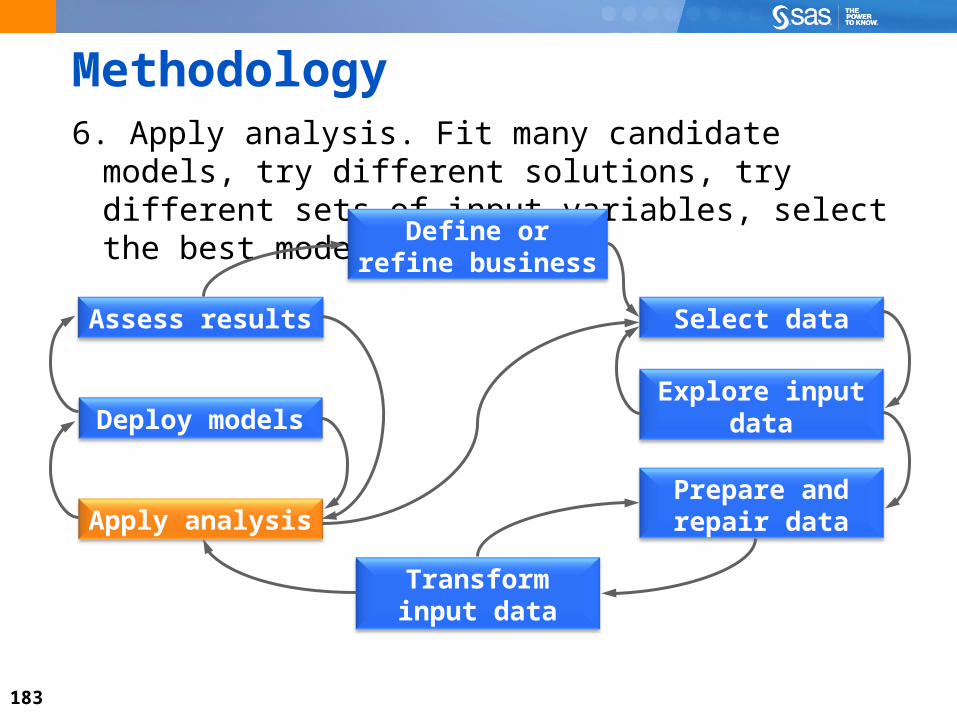
Methodology6. Apply analysis. Fit many candidate models, try different
solutions, try different sets of input variables, select the best model.
Select data
Define or refine business objective
Assess results
Deploy modelsExplore input
data
Prepare and repair data
Transform input data
Apply analysis
184
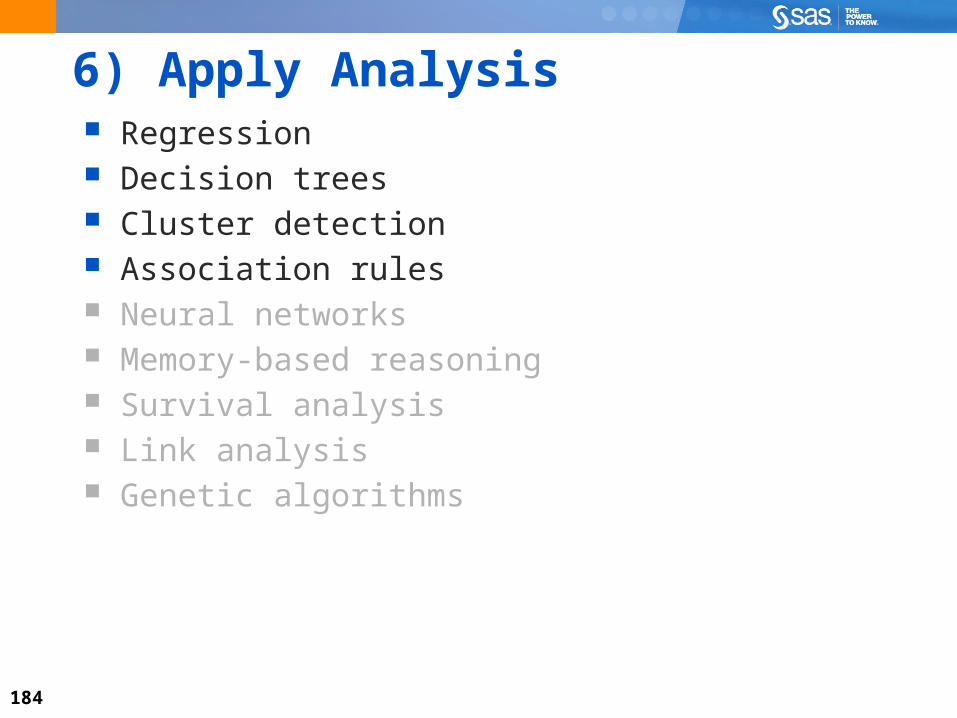
6) Apply Analysis Regression Decision trees Cluster detection Association rules Neural networks Memory-based reasoning Survival analysis Link analysis Genetic algorithms
185
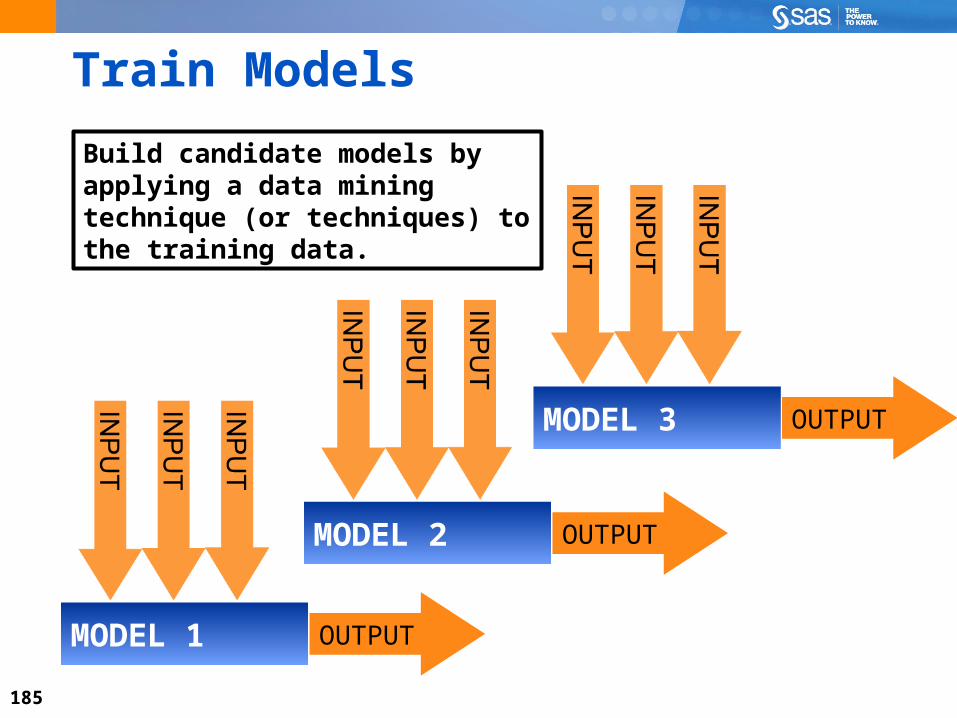
Train Models
MODEL 1 OUTPUT
Build candidate models by applying a data mining technique (or techniques) to the training data.
MODEL 2 OUTPUT
MODEL 3 OUTPUT
186
Assess Models
Assess models by applying the models to the validation data set.
MODEL 1 OUTPUT
MODEL 2 OUTPUT
MODEL 3 OUTPUT

187
Assess ModelsScore the validation data using the candidate models and then compare the results. Select the model with the best performance on the validation data set.
Communicate model assessments through quantitative measures graphs.
188
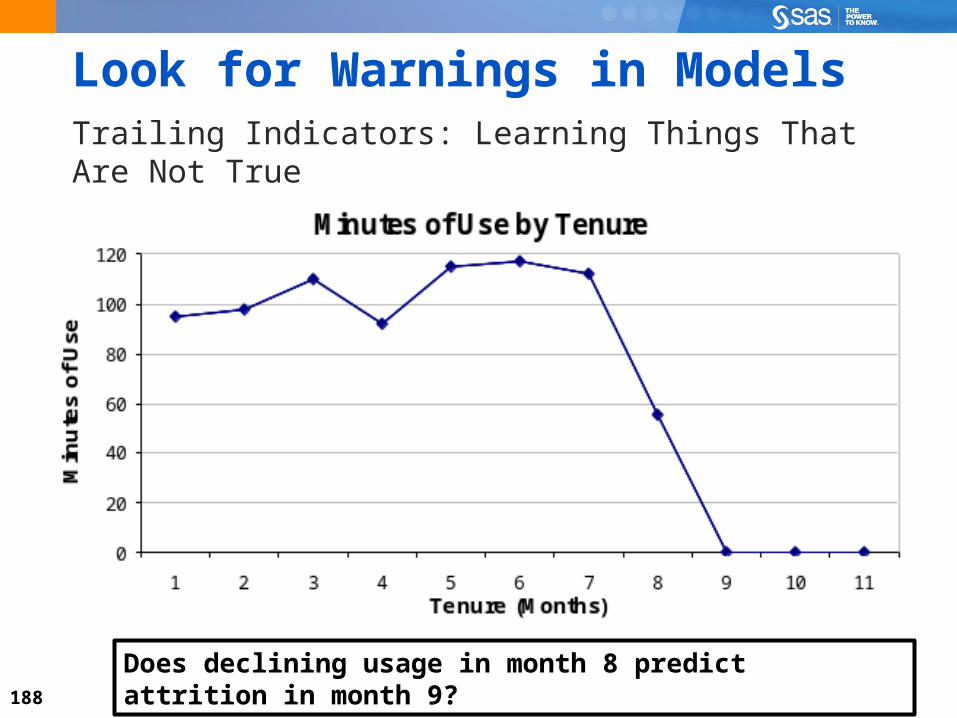
Look for Warnings in ModelsTrailing Indicators: Learning Things That Are Not True
What happens in month 8?
Does declining usage in month 8 predict attrition in month 9?

189
Look for Warnings in ModelsPerfect Models: Things that are too good to be true.
100% of customers who spoke to a customer support representative canceled a contract.
Eureka! It’s all I need to know!
If a customer cancels, that customer is automatically flagged to get a call from customer support.
The information is useless in predicting cancellation.
Models that seem too good usually are.

190
Idea ExchangeWhat are some other warning signs that you can think of in modeling? Have you experienced any pitfalls that were memorable or that changed how you approach the data analysis objectives?
191
Methodology7. Deploy models. Score new observations, make model-
based decisions. Gather results of model deployment.
Select data
Define or refine business objective
Assess results
Deploy modelsExplore input
data
Prepare and repair data
Transform input data
Apply analysis

192
7) Deploy Models and Score New Data
193
Methodology8. Assess the usefulness of the model. If the model has
gone stale, revise it.
Select data
Define or refine business objective
Assess results
Deploy modelsExplore input
data
Prepare and repair data
Transform input data
Apply analysis

194
8) Assess Results Compare actual results against expectations. Compare the challenger’s results against
the champion’s. Did the model find the right people? Did the action affect their behavior? What are the characteristics of the customers
most affected by the intervention?

195
Good Test Design Measures the Impact of Both the Message and the Model
Control Group
Chosen at random; receives message.
Response measures message without model.
Target Group
Chosen by model; receives message.
Response measures message with model.
Holdout Group
Chosen at random; receives no message.
Response measures background response.
Modeled Holdout
Chosen by model; receives no message.
Response measures model without message.
Picked by Model
Mes
sage
NO
NO
YES
YE
SImpact of model on group getting message
Impact of message on group with good model scores
196
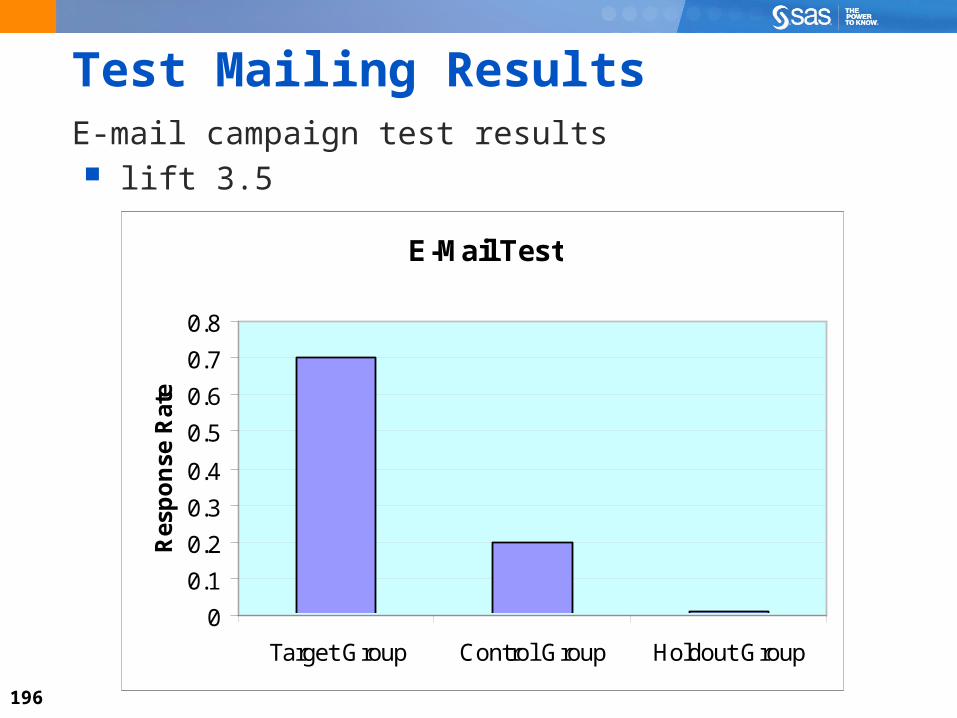
Test Mailing ResultsE-mail campaign test results lift 3.5
E-Mail Test
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
Target Group Control Group Holdout Group
Res
po
nse
Rat
e
197
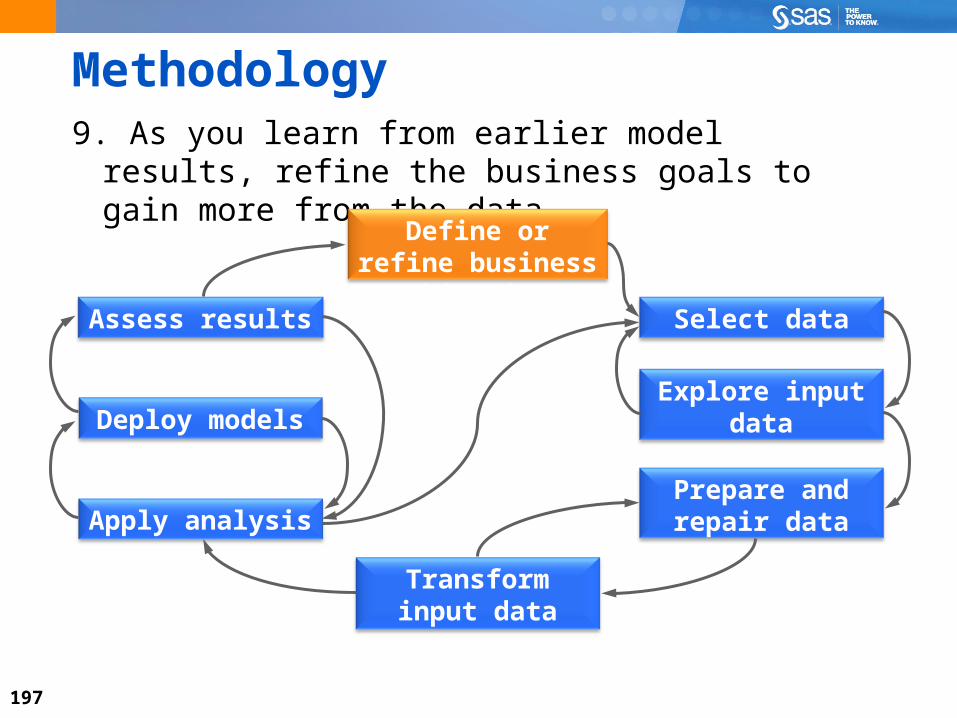
Methodology9. As you learn from earlier model results, refine the
business goals to gain more from the data.
Select data
Define or refine business objective
Assess results
Deploy modelsExplore input
data
Prepare and repair data
Transform input data
Apply analysis

198
9) Begin AgainRevisit business objectives.
Define new objectives.
Gather and evaluate new data. model scores cluster assignments responses
Example:
A model discovers that geography is a good predictor of churn. What do the high-churn geographies have in common? Is the pattern your model discovered stable over time?

199
Lessons LearnedData miners must be careful to avoid pitfalls, particularly with regard to spurious patterns in the data: learning things that are not true or not useful confusing signal and noise creating unstable models
A methodology is a way of being careful.

200
Idea ExchangeOutline a business objective of your own in terms of the methodology described here.
What is your business objective? Can you frame it in terms of a data mining problem? How will you select the data? What are the inputs? What do you want to look at to get familiar with the data?
continued...

201
Idea ExchangeAnticipate any data quality problems that you might encounter and how you could go about fixing them.
Do any variables require transformation?
Proceed through the remaining steps of the methodology as you consider your example.

202
Basic Data ModelingA common approach to modeling customer value is RFM analysis, so named because it uses three key variables: Recency – how long it has been since the customer’s last
purchase Frequency – how many times the customer has purchased
something Monetary value – how much money the customer has
spent
RFM variables tend to predict responses to marketing campaigns effectively.
RFM is a special case of OLAP.
203
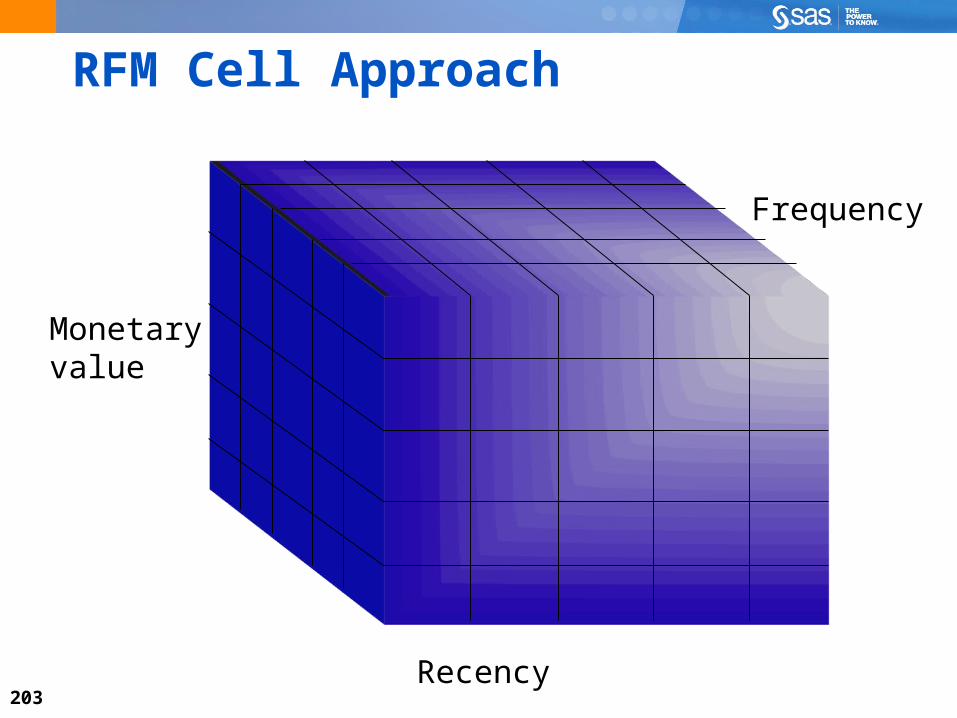
RFM Cell Approach
Recency
Frequency
Monetaryvalue

204
RFM Cell ApproachA typical approach to RFM analysis is to bin customers into (approximately) equal-sized groups on each of the rank-ordered R,F, and M variables. For example: Bin five groups on R (highest bin = most recent) Bin five groups on F (highest bin = most frequent) Bin five groups on M (highest bin = highest value)
The combination of the bins gives an RFM “score” that can be compared to some target or outcome variable.
Customer score 555 = most recent quintile, most frequent quintile, highest spending quintile.

205
Computing Profitability in RFMBreak-even response rate =
current cost of promotion per dollar of net profit.
Cost of promotion to an individual
Average net profit per sale
Example: It costs $2.00 to print and mail each catalog. Average net profit per transaction is $30.
2.00/30.00 = 0.067
Profitable RFM cells are those with a response rate greater than 6.7%.

206
RFM Analysis of the Catalog Data Recode recency so that the highest values are the
most recent. Bin the R, F, and M variables into five groups each,
numbered 1-5, so that 1 is the least valuable and 5 is the most valuable bin.
Concatenate the RFM variables to obtain a single RFM “score.”
Graphically investigate the response rates for the different groups.

207
Performing RFM Analysis of the Catalog Data
Catalog Case Study
Task: Perform RFM analysis on the catalog data.

208
Performing Graphical RFM Analysis
Catalog Case Study
Task: Perform graphical RFM analysis.

209
Limitations of RFMOnly uses three variables Modern data collection processes offer rich information about
preferences, behaviors, attitudes, and demographics.
Scores are entirely categorical 515 and 551 and 155 are equally good, if RFM variables are
of equal importance. Sorting by the RFM values is not informative and
overemphasizes recency.
So many categories The simple example above results in 125 groups.
Not very useful for finding prospective customers Statistics are descriptive.

210
Idea ExchangeWould RFM analysis apply to a business objective that you are considering? If so, what would be your R, F, and M variables?
What other basic analytical techniques could you use to explore your data and get preliminary answers to your questions?

211
Exercise ScenarioPractice with a charity direct mail example.
Analysis Goal:
A veteran’s organization seeks continued contributions from lapsing donors. Use lapsing donor response from an earlier campaign to predict future lapsing donor response.
211
...

212
Exercise ScenarioPractice with a charity direct mail example.
Analysis Goal:
A veteran’s organization seeks continued contributions from lapsing donors. Use lapsing donor response from an earlier campaign to predict future lapsing donor response.
Exercise Data (PVA97NK): The data is extracted from previous year’s campaign. The sample is balanced with regard to
response/non-response rate. The actual response rate is approximately 5%.
212

213
R, F, M Variables in the Charity Data SetIn the data set PVA97NK, the following variables should be used for RFM analysis:
GiftTimeLast Time since last gift (Recency)
GiftCntAll Gift count over all months (Frequency)
Monetary value must be computed as follows:
GiftAvgAll*GiftCntAll Average gift amount over lifetime * total gift count
Use SAS Enterprise Miner to create the RFM variables and bins, and then perform graphical RFM analysis.
213
214
Exercise
This exercise reinforces the concepts discussed previously.

215
Chapter 2: Basics of Business Analytics
2.1 Overview of Techniques
2.2 Data Management
2.3 Data Difficulties
2.4 SAS Enterprise Miner: A Primer
2.5 Honest Assessment
2.6 Methodology
2.7 Recommended Reading2.7 Recommended Reading

216
Recommended ReadingDavenport, Thomas H., Jeanne G. Harris, and Robert Morison. 2010. Analytics at Work: Smarter Decisions, Better Results. Boston: Harvard Business Press. Chapters 2 through 6, the DELTA method
These chapters present a complementary perspective to this chapter on how to integrate analytics at various levels of the organization.